Compare commits
205 commits
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ebcc6e5086 | ||
|
|
c0766f6abc | ||
|
|
7bc90c425f | ||
|
|
f2c494d4d6 | ||
|
|
8147bbf3b9 | ||
|
|
adbeeaf203 | ||
|
|
f55ed56215 | ||
|
|
d1d33c4bce | ||
|
|
b7de08ba0b | ||
|
|
405cef8d28 | ||
|
|
21262d2e43 | ||
|
|
75d64f9dc6 | ||
|
|
929448d64b | ||
|
|
134aad29f1 | ||
|
|
dcd4d7a7a8 | ||
|
|
e0c26c0952 | ||
|
|
9fa2d0b6ca | ||
|
|
0877e34289 | ||
|
|
92c3d3840d | ||
|
|
98017e9a76 | ||
|
|
6932c38854 | ||
|
|
ecdb5ef859 | ||
|
|
81c44f5f4e | ||
|
|
59c07e315a | ||
|
|
07f8ec41a1 | ||
|
|
01e52e795a | ||
|
|
98ec0f5e0c | ||
|
|
eb3d7a183a | ||
|
|
93aebedd7d | ||
|
|
616daec0d9 | ||
|
|
745462d3ae | ||
|
|
0634c1e05f | ||
|
|
b230b693f8 | ||
|
|
97a0d00bfd | ||
|
|
f2f0f426aa | ||
|
|
7be5905b46 | ||
|
|
7c9e91f91a | ||
|
|
586e9a613b | ||
|
|
e61efcd00d | ||
|
|
9311d924f7 | ||
|
|
8947d3cb19 | ||
|
|
2150363108 | ||
|
|
6a9a2ad40f | ||
|
|
55eb8818ea | ||
|
|
a48564e3b2 | ||
|
|
606e9bb0d6 | ||
|
|
abc5184e19 | ||
|
|
99ddd208db | ||
|
|
fc234b12e5 | ||
|
|
04d747ff99 | ||
|
|
4586b344ce | ||
|
|
9b17822229 | ||
|
|
0f33f2bfef | ||
|
|
bc4e3aa7fb | ||
|
|
e60bb35ebd | ||
|
|
024aceda53 | ||
|
|
6155700a68 | ||
|
|
9b3618f73e | ||
|
|
911f483ce3 | ||
|
|
09e1aba567 | ||
|
|
66c63f0511 | ||
|
|
115fd217e8 | ||
|
|
27520c835e | ||
|
|
c686187e35 | ||
|
|
ee02a80a98 | ||
|
|
bb6166c62d | ||
|
|
08f25a7c50 | ||
|
|
292ad2b9b6 | ||
|
|
2627f02a55 | ||
|
|
18e0571e81 | ||
|
|
807e6151f2 | ||
|
|
8a1f0f7f33 | ||
|
|
3cf620ed8e | ||
|
|
75d53c3c6f | ||
|
|
59043a9add | ||
|
|
f7eca425eb | ||
|
|
84b978278e | ||
|
|
579f95f9fc | ||
|
|
99e1006cb5 | ||
|
|
4958097b66 | ||
|
|
cd9b91e1d9 | ||
|
|
fc38bda03c | ||
|
|
c53d2b6f5a | ||
|
|
570bda9c8b | ||
|
|
34c5ab2e56 | ||
|
|
4bc2bf79eb | ||
|
|
db3294e6e0 | ||
|
|
93850d72eb | ||
|
|
c6cc3cbd26 | ||
|
|
23599ee1b2 | ||
|
|
42584ca60a | ||
|
|
d57fc7eab9 | ||
|
|
4845b92248 | ||
|
|
9ad09c7c6d | ||
|
|
35483fa0b1 | ||
|
|
bffd1b1394 | ||
|
|
34e3f9ecee | ||
|
|
9df8f9c651 | ||
|
|
0918299163 | ||
|
|
a46343c84f | ||
|
|
eb87474b48 | ||
|
|
fc9b0af5b6 | ||
|
|
a41abc870d | ||
|
|
78e9d7b50b | ||
|
|
a10beac943 | ||
|
|
9e3963ba23 | ||
|
|
3b2b8f814c | ||
|
|
2363865e00 | ||
|
|
903a44d991 | ||
|
|
6b46f0488d | ||
|
|
c3703fd13f | ||
|
|
79b84d89a3 | ||
|
|
ac01a17214 | ||
|
|
a86388f6de | ||
|
|
4b90097997 | ||
|
|
0094237b97 | ||
|
|
028143ec7e | ||
|
|
ea7b55f1f0 | ||
|
|
b069e3d824 | ||
|
|
2038877e4e | ||
|
|
6c0f901d33 | ||
|
|
1a5fd214b9 | ||
|
|
5512a841e1 | ||
|
|
983955f5d0 | ||
|
|
23ac3fcd89 | ||
|
|
9dbd8cab4b | ||
|
|
6fd718f353 | ||
|
|
09ea58c062 | ||
|
|
fbe68d516c | ||
|
|
4187afd165 | ||
|
|
5d44018018 | ||
|
|
287de0807c | ||
|
|
e9be86229d | ||
|
|
237b78ee63 | ||
|
|
f1d51eae7b | ||
|
|
709ea1ebcb | ||
|
|
9f2e329d99 | ||
|
|
76dd9c392b | ||
|
|
78bd2da267 | ||
|
|
0901f67d89 | ||
|
|
66278443c4 | ||
|
|
c11aba7aa4 | ||
|
|
c43ec575ae | ||
|
|
a7e6bcb366 | ||
|
|
fb98a4d7d0 | ||
|
|
75e9123eaf | ||
|
|
7263ec553e | ||
|
|
4466bb1451 | ||
|
|
e9f2b1efea | ||
|
|
cb1ed3beb1 | ||
|
|
e5713dc63c | ||
|
|
9a6f2a6d96 | ||
|
|
844bdbdf60 | ||
|
|
8d125f8d44 | ||
|
|
36c1471dcf | ||
|
|
9e9c778edd | ||
|
|
87c8457144 | ||
|
|
b873f75ff6 | ||
|
|
706971edbe | ||
|
|
f8022c9c9a | ||
|
|
4f7d2af1fa | ||
|
|
a919a3a519 | ||
|
|
37fc334c46 | ||
|
|
30e295ec28 | ||
|
|
301a0ca66d | ||
|
|
060e423707 | ||
|
|
0da235bceb | ||
|
|
27e09d7aa7 | ||
|
|
0eeab397cf | ||
|
|
3b7850802a | ||
|
|
14b14686f4 | ||
|
|
830ee294ef | ||
|
|
25a8c6b558 | ||
|
|
f747637688 | ||
|
|
bf1667b44d | ||
|
|
51a753c4d2 | ||
|
|
32c21a26a9 | ||
|
|
708c45504a | ||
|
|
460a06ec04 | ||
|
|
f91d2be91e | ||
|
|
d244136efd | ||
|
|
e4ac106b98 | ||
|
|
869fc1698c | ||
|
|
02922845dd | ||
|
|
c5f18a4166 | ||
|
|
195bc7c69d | ||
|
|
19ac0e83ad | ||
|
|
d6d758c5c1 | ||
|
|
9fa232e3a1 | ||
|
|
a00b11822a | ||
|
|
5d0868704b | ||
|
|
bda9561178 | ||
|
|
6f22767486 | ||
|
|
b230a13761 | ||
|
|
53206a0861 | ||
|
|
10baf47c02 | ||
|
|
7f277dda2f | ||
|
|
5a0af081e6 | ||
|
|
a1e5d22570 | ||
|
|
ca39d38dda | ||
|
|
9efddcdbf9 | ||
|
|
95495aa786 | ||
|
|
9525c86a78 | ||
|
|
a9a4f87628 | ||
|
|
4e8c8d4054 |
120 changed files with 6656 additions and 3680 deletions
77
.github/workflows/docker-image.yml
vendored
77
.github/workflows/docker-image.yml
vendored
|
|
@ -1,16 +1,79 @@
|
|||
name: Docker Image CI
|
||||
name: Publish Docker Image
|
||||
|
||||
on:
|
||||
push:
|
||||
branches: [ master ]
|
||||
branches:
|
||||
- 'master'
|
||||
- 'development'
|
||||
tags:
|
||||
- '*'
|
||||
|
||||
env:
|
||||
# github.repository as <account>/<repo>
|
||||
IMAGE_NAME: lbry/hub
|
||||
|
||||
jobs:
|
||||
login:
|
||||
build:
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
contents: read
|
||||
packages: write
|
||||
# This is used to complete the identity challenge
|
||||
# with sigstore/fulcio when running outside of PRs.
|
||||
id-token: write
|
||||
|
||||
steps:
|
||||
-
|
||||
name: Login to Docker Hub
|
||||
uses: docker/login-action@v1
|
||||
- name: Checkout repository
|
||||
uses: actions/checkout@v3
|
||||
|
||||
# # Install the cosign tool except on PR
|
||||
# # https://github.com/sigstore/cosign-installer
|
||||
# - name: Install cosign
|
||||
# if: github.event_name != 'pull_request'
|
||||
# uses: sigstore/cosign-installer@d6a3abf1bdea83574e28d40543793018b6035605
|
||||
# with:
|
||||
# cosign-release: 'v1.7.1'
|
||||
|
||||
# Workaround: https://github.com/docker/build-push-action/issues/461
|
||||
- name: Setup Docker buildx
|
||||
uses: docker/setup-buildx-action@v2
|
||||
|
||||
# Login against a Docker registry except on PR
|
||||
# https://github.com/docker/login-action
|
||||
- name: Log into registry ${{ env.REGISTRY }}
|
||||
if: github.event_name != 'pull_request'
|
||||
uses: docker/login-action@v2
|
||||
with:
|
||||
username: ${{ secrets.DOCKERHUB_USERNAME }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
password: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
|
||||
# Extract metadata (tags, labels) for Docker
|
||||
# https://github.com/docker/metadata-action
|
||||
- name: Extract Docker metadata
|
||||
id: meta
|
||||
uses: docker/metadata-action@v2
|
||||
with:
|
||||
images: ${{ env.IMAGE_NAME }}
|
||||
|
||||
# Build and push Docker image with Buildx (don't push on PR)
|
||||
# https://github.com/docker/build-push-action
|
||||
- name: Build and push Docker image
|
||||
id: build-and-push
|
||||
uses: docker/build-push-action@v3
|
||||
with:
|
||||
context: .
|
||||
push: ${{ github.event_name != 'pull_request' }}
|
||||
tags: ${{ env.IMAGE_NAME }}:${{ github.ref_name }}
|
||||
|
||||
# # Sign the resulting Docker image digest except on PRs.
|
||||
# # This will only write to the public Rekor transparency log when the Docker
|
||||
# # repository is public to avoid leaking data. If you would like to publish
|
||||
# # transparency data even for private images, pass --force to cosign below.
|
||||
# # https://github.com/sigstore/cosign
|
||||
# - name: Sign the published Docker image
|
||||
# if: ${{ github.event_name != 'pull_request' }}
|
||||
# env:
|
||||
# COSIGN_EXPERIMENTAL: "true"
|
||||
# # This step uses the identity token to provision an ephemeral certificate
|
||||
# # against the sigstore community Fulcio instance.
|
||||
# run: cosign sign ${{ steps.meta.outputs.tags }}@${{ steps.build-and-push.outputs.digest }}
|
||||
|
|
|
|||
|
|
@ -35,22 +35,12 @@ USER $user
|
|||
WORKDIR $projects_dir
|
||||
RUN python3.9 -m pip install pip
|
||||
RUN python3.9 -m pip install -e .
|
||||
RUN python3.9 docker/set_build.py
|
||||
RUN python3.9 scripts/set_build.py
|
||||
RUN rm ~/.cache -rf
|
||||
|
||||
# entry point
|
||||
ARG host=localhost
|
||||
ARG tcp_port=50001
|
||||
ARG daemon_url=http://lbry:lbry@localhost:9245/
|
||||
VOLUME $db_dir
|
||||
ENV TCP_PORT=$tcp_port
|
||||
ENV HOST=$host
|
||||
ENV DAEMON_URL=$daemon_url
|
||||
ENV DB_DIRECTORY=$db_dir
|
||||
ENV MAX_SESSIONS=100000
|
||||
ENV MAX_SEND=1000000000000000000
|
||||
ENV MAX_RECEIVE=1000000000000000000
|
||||
|
||||
|
||||
COPY ./docker/scribe_entrypoint.sh /entrypoint.sh
|
||||
COPY ./scripts/entrypoint.sh /entrypoint.sh
|
||||
ENTRYPOINT ["/entrypoint.sh"]
|
||||
95
README.md
95
README.md
|
|
@ -1,69 +1,110 @@
|
|||
## Scribe
|
||||
## LBRY Hub
|
||||
|
||||
Scribe is a python library for building services that use the processed data from the [LBRY blockchain](https://github.com/lbryio/lbrycrd) in an ongoing manner. Scribe contains a set of three core executable services that are used together:
|
||||
* `scribe` ([scribe.blockchain.service](https://github.com/lbryio/scribe/tree/master/scribe/blockchain/service.py)) - maintains a [rocksdb](https://github.com/lbryio/lbry-rocksdb) database containing the LBRY blockchain.
|
||||
* `scribe-hub` ([scribe.hub.service](https://github.com/lbryio/scribe/tree/master/scribe/hub/service.py)) - an electrum server for thin-wallet clients (such as [lbry-sdk](https://github.com/lbryio/lbry-sdk)), provides an api for clients to use thin simple-payment-verification (spv) wallets and to resolve and search claims published to the LBRY blockchain.
|
||||
* `scribe-elastic-sync` ([scribe.elasticsearch.service](https://github.com/lbryio/scribe/tree/master/scribe/elasticsearch/service.py)) - a utility to maintain an elasticsearch database of metadata for claims in the LBRY blockchain
|
||||
This repo provides a python library, `hub`, for building services that use the processed data from the [LBRY blockchain](https://github.com/lbryio/lbrycrd) in an ongoing manner. Hub contains a set of three core executable services that are used together:
|
||||
* `scribe` ([hub.scribe.service](https://github.com/lbryio/hub/tree/master/hub/service.py)) - maintains a [rocksdb](https://github.com/lbryio/lbry-rocksdb) database containing the LBRY blockchain.
|
||||
* `herald` ([hub.herald.service](https://github.com/lbryio/hub/tree/master/hub/herald/service.py)) - an electrum server for thin-wallet clients (such as [lbry-sdk](https://github.com/lbryio/lbry-sdk)), provides an api for clients to use thin simple-payment-verification (spv) wallets and to resolve and search claims published to the LBRY blockchain. A drop in replacement port of herald written in go - [herald.go](https://github.com/lbryio/herald.go) is currently being worked on.
|
||||
* `scribe-elastic-sync` ([hub.elastic_sync.service](https://github.com/lbryio/hub/tree/master/hub/elastic_sync/service.py)) - a utility to maintain an elasticsearch database of metadata for claims in the LBRY blockchain
|
||||
|
||||
Features and overview of scribe as a python library:
|
||||
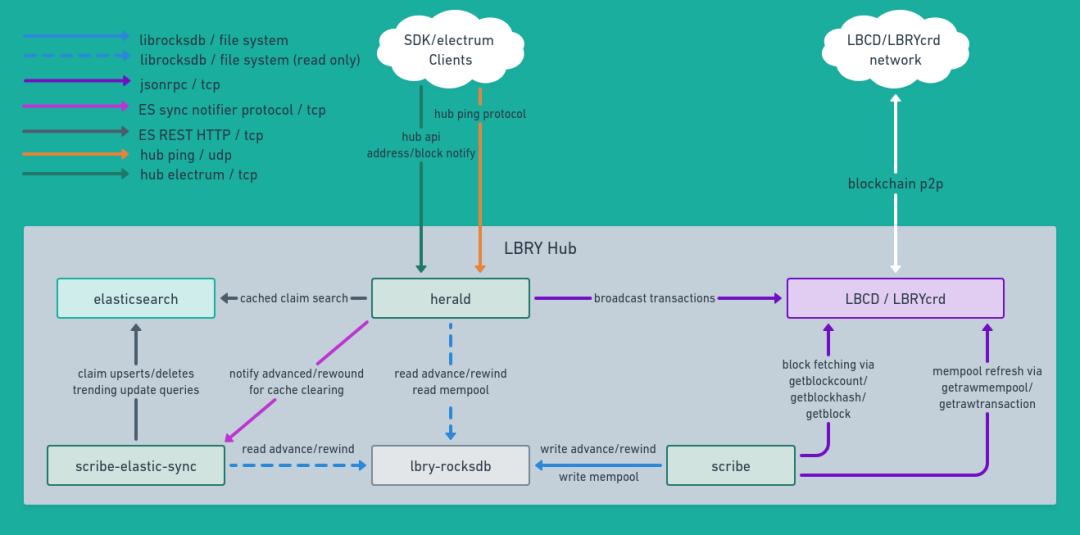
|
||||
|
||||
Features and overview of `hub` as a python library:
|
||||
* Uses Python 3.7-3.9 (3.10 probably works but hasn't yet been tested)
|
||||
* An interface developers may implement in order to build their own applications able to receive up-to-date blockchain data in an ongoing manner ([scribe.service.BlockchainReaderService](https://github.com/lbryio/scribe/tree/master/scribe/service.py))
|
||||
* Protobuf schema for encoding and decoding metadata stored on the blockchain ([scribe.schema](https://github.com/lbryio/scribe/tree/master/scribe/schema))
|
||||
* [Rocksdb 6.25.3](https://github.com/lbryio/lbry-rocksdb/) based database containing the blockchain data ([scribe.db](https://github.com/lbryio/scribe/tree/master/scribe/db))
|
||||
* [A community driven performant trending algorithm](https://raw.githubusercontent.com/lbryio/scribe/master/scribe/elasticsearch/trending%20algorithm.pdf) for searching claims ([code](https://github.com/lbryio/scribe/blob/master/scribe/elasticsearch/fast_ar_trending.py))
|
||||
* An interface developers may implement in order to build their own applications able to receive up-to-date blockchain data in an ongoing manner ([hub.service.BlockchainReaderService](https://github.com/lbryio/hub/tree/master/hub/service.py))
|
||||
* Protobuf schema for encoding and decoding metadata stored on the blockchain ([hub.schema](https://github.com/lbryio/hub/tree/master/hub/schema))
|
||||
* [Rocksdb 6.25.3](https://github.com/lbryio/lbry-rocksdb/) based database containing the blockchain data ([hub.db](https://github.com/lbryio/hub/tree/master/hub/db))
|
||||
* [A community driven performant trending algorithm](https://raw.githubusercontent.com/lbryio/hub/master/docs/trending%20algorithm.pdf) for searching claims ([code](https://github.com/lbryio/hub/blob/master/hub/elastic_sync/fast_ar_trending.py))
|
||||
|
||||
## Installation
|
||||
|
||||
Scribe may be run from source, a binary, or a docker image.
|
||||
Our [releases page](https://github.com/lbryio/scribe/releases) contains pre-built binaries of the latest release, pre-releases, and past releases for macOS and Debian-based Linux.
|
||||
Prebuilt [docker images](https://hub.docker.com/r/lbry/scribe/latest-release) are also available.
|
||||
Our [releases page](https://github.com/lbryio/hub/releases) contains pre-built binaries of the latest release, pre-releases, and past releases for macOS and Debian-based Linux.
|
||||
Prebuilt [docker images](https://hub.docker.com/r/lbry/hub/tags) are also available.
|
||||
|
||||
### Prebuilt docker image
|
||||
|
||||
`docker pull lbry/scribe:latest-release`
|
||||
`docker pull lbry/hub:master`
|
||||
|
||||
### Build your own docker image
|
||||
|
||||
```
|
||||
git clone https://github.com/lbryio/scribe.git
|
||||
cd scribe
|
||||
docker build -f ./docker/Dockerfile.scribe -t lbry/scribe:development .
|
||||
git clone https://github.com/lbryio/hub.git
|
||||
cd hub
|
||||
docker build -t lbry/hub:development .
|
||||
```
|
||||
|
||||
### Install from source
|
||||
|
||||
Scribe has been tested with python 3.7-3.9. Higher versions probably work but have not yet been tested.
|
||||
|
||||
1. clone the scribe scribe
|
||||
1. clone the scribe repo
|
||||
```
|
||||
git clone https://github.com/lbryio/scribe.git
|
||||
cd scribe
|
||||
git clone https://github.com/lbryio/hub.git
|
||||
cd hub
|
||||
```
|
||||
2. make a virtual env
|
||||
```
|
||||
python3.9 -m venv scribe-venv
|
||||
python3.9 -m venv hub-venv
|
||||
```
|
||||
3. from the virtual env, install scribe
|
||||
```
|
||||
source scribe-venv/bin/activate
|
||||
source hub-venv/bin/activate
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
That completes the installation, now you should have the commands `scribe`, `scribe-elastic-sync` and `herald`
|
||||
|
||||
These can also optionally be run with `python -m hub.scribe`, `python -m hub.elastic_sync`, and `python -m hub.herald`
|
||||
|
||||
## Usage
|
||||
|
||||
Scribe needs either the [lbrycrd](https://github.com/lbryio/lbrycrd) or [lbcd](https://github.com/lbryio/lbcd) blockchain daemon to be running.
|
||||
### Requirements
|
||||
|
||||
As of block 1124663 (3/10/22) the size of the rocksdb database is 87GB and the size of the elasticsearch volume is 49GB.
|
||||
Scribe needs elasticsearch and either the [lbrycrd](https://github.com/lbryio/lbrycrd) or [lbcd](https://github.com/lbryio/lbcd) blockchain daemon to be running.
|
||||
|
||||
With options for high performance, if you have 64gb of memory and 12 cores, everything can be run on the same machine. However, the recommended way is with elasticsearch on one instance with 8gb of memory and at least 4 cores dedicated to it and the blockchain daemon on another with 16gb of memory and at least 4 cores. Then the scribe hub services can be run their own instance with between 16 and 32gb of memory (depending on settings) and 8 cores.
|
||||
|
||||
As of block 1147423 (4/21/22) the size of the scribe rocksdb database is 120GB and the size of the elasticsearch volume is 63GB.
|
||||
|
||||
### docker-compose
|
||||
The recommended way to run a scribe hub is with docker. See [this guide](https://github.com/lbryio/hub/blob/master/docs/cluster_guide.md) for instructions.
|
||||
|
||||
If you have the resources to run all of the services on one machine (at least 300gb of fast storage, preferably nvme, 64gb of RAM, 12 fast cores), see [this](https://github.com/lbryio/hub/blob/master/docs/docker_examples/docker-compose.yml) docker-compose example.
|
||||
|
||||
### From source
|
||||
|
||||
To start scribe, run the following (providing your own args)
|
||||
### Options
|
||||
|
||||
```
|
||||
scribe --db_dir /your/db/path --daemon_url rpcuser:rpcpass@localhost:9245
|
||||
```
|
||||
#### Content blocking and filtering
|
||||
|
||||
For various reasons it may be desirable to block or filtering content from claim search and resolve results, [here](https://github.com/lbryio/hub/blob/master/docs/blocking.md) are instructions for how to configure and use this feature as well as information about the recommended defaults.
|
||||
|
||||
#### Common options across `scribe`, `herald`, and `scribe-elastic-sync`:
|
||||
- `--db_dir` (required) Path of the directory containing lbry-rocksdb, set from the environment with `DB_DIRECTORY`
|
||||
- `--daemon_url` (required for `scribe` and `herald`) URL for rpc from lbrycrd or lbcd<rpcuser>:<rpcpassword>@<lbrycrd rpc ip><lbrycrd rpc port>.
|
||||
- `--reorg_limit` Max reorg depth, defaults to 200, set from the environment with `REORG_LIMIT`.
|
||||
- `--chain` With blockchain to use - either `mainnet`, `testnet`, or `regtest` - set from the environment with `NET`
|
||||
- `--max_query_workers` Size of the thread pool, set from the environment with `MAX_QUERY_WORKERS`
|
||||
- `--cache_all_tx_hashes` If this flag is set, all tx hashes will be stored in memory. For `scribe`, this speeds up the rate it can apply blocks as well as process mempool. For `herald`, this will speed up syncing address histories. This setting will use 10+g of memory. It can be set from the environment with `CACHE_ALL_TX_HASHES=Yes`
|
||||
- `--cache_all_claim_txos` If this flag is set, all claim txos will be indexed in memory. Set from the environment with `CACHE_ALL_CLAIM_TXOS=Yes`
|
||||
- `--prometheus_port` If provided this port will be used to provide prometheus metrics, set from the environment with `PROMETHEUS_PORT`
|
||||
|
||||
#### Options for `scribe`
|
||||
- `--db_max_open_files` This setting translates into the max_open_files option given to rocksdb. A higher number will use more memory. Defaults to 64.
|
||||
- `--address_history_cache_size` The count of items in the address history cache used for processing blocks and mempool updates. A higher number will use more memory, shouldn't ever need to be higher than 10000. Defaults to 1000.
|
||||
- `--index_address_statuses` Maintain an index of the statuses of address transaction histories, this makes handling notifications for transactions in a block uniformly fast at the expense of more time to process new blocks and somewhat more disk space (~10gb as of block 1161417).
|
||||
|
||||
#### Options for `scribe-elastic-sync`
|
||||
- `--reindex` If this flag is set drop and rebuild the elasticsearch index.
|
||||
|
||||
#### Options for `herald`
|
||||
- `--host` Interface for server to listen on, use 0.0.0.0 to listen on the external interface. Can be set from the environment with `HOST`
|
||||
- `--tcp_port` Electrum TCP port to listen on for hub server. Can be set from the environment with `TCP_PORT`
|
||||
- `--udp_port` UDP port to listen on for hub server. Can be set from the environment with `UDP_PORT`
|
||||
- `--elastic_services` Comma separated list of items in the format `elastic_host:elastic_port/notifier_host:notifier_port`. Can be set from the environment with `ELASTIC_SERVICES`
|
||||
- `--query_timeout_ms` Timeout for claim searches in elasticsearch in milliseconds. Can be set from the environment with `QUERY_TIMEOUT_MS`
|
||||
- `--blocking_channel_ids` Space separated list of channel claim ids used for blocking. Claims that are reposted by these channels can't be resolved or returned in search results. Can be set from the environment with `BLOCKING_CHANNEL_IDS`.
|
||||
- `--filtering_channel_ids` Space separated list of channel claim ids used for blocking. Claims that are reposted by these channels aren't returned in search results. Can be set from the environment with `FILTERING_CHANNEL_IDS`
|
||||
- `--index_address_statuses` Use the address history status index, this makes handling notifications for transactions in a block uniformly fast (must be turned on in `scribe` too).
|
||||
|
||||
## Contributing
|
||||
|
||||
|
|
|
|||
BIN
diagram.png
BIN
diagram.png
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 142 KiB |
|
|
@ -1,80 +0,0 @@
|
|||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbry_rocksdb:
|
||||
es01:
|
||||
|
||||
services:
|
||||
scribe:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
image: lbry/scribe:${SCRIBE_TAG:-latest-release}
|
||||
restart: always
|
||||
network_mode: host
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe
|
||||
- DAEMON_URL=http://lbry:lbry@127.0.0.1:9245
|
||||
- MAX_QUERY_WORKERS=2
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6
|
||||
scribe_elastic_sync:
|
||||
depends_on:
|
||||
- es01
|
||||
image: lbry/scribe:${SCRIBE_TAG:-latest-release}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "127.0.0.1:19080:19080" # elastic notifier port
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe-elastic-sync
|
||||
- MAX_QUERY_WORKERS=2
|
||||
- ELASTIC_HOST=127.0.0.1
|
||||
- ELASTIC_PORT=9200
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6
|
||||
scribe_hub:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
- scribe
|
||||
image: lbry/scribe:${SCRIBE_TAG:-latest-release}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "50001:50001" # electrum rpc port and udp ping port
|
||||
- "2112:2112" # comment out to disable prometheus
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe-hub
|
||||
- DAEMON_URL=http://lbry:lbry@127.0.0.1:9245 # used for broadcasting transactions
|
||||
- MAX_QUERY_WORKERS=4 # reader threads
|
||||
- MAX_SESSIONS=100000
|
||||
- ELASTIC_HOST=127.0.0.1
|
||||
- ELASTIC_PORT=9200
|
||||
- HOST=0.0.0.0
|
||||
- PROMETHEUS_PORT=2112
|
||||
- TCP_PORT=50001
|
||||
- ALLOW_LAN_UDP=No
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6
|
||||
es01:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.16.0
|
||||
container_name: es01
|
||||
environment:
|
||||
- node.name=es01
|
||||
- discovery.type=single-node
|
||||
- indices.query.bool.max_clause_count=8192
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms8g -Xmx8g" # no more than 32, remember to disable swap
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- "es01:/usr/share/elasticsearch/data"
|
||||
ports:
|
||||
- "127.0.0.1:9200:9200"
|
||||
|
|
@ -1,7 +0,0 @@
|
|||
#!/bin/bash
|
||||
|
||||
DIR="$( cd "$( dirname "${BASH_SOURCE[0]}" )" >/dev/null 2>&1 && pwd )"
|
||||
cd "$DIR/../.." ## make sure we're in the right place. Docker Hub screws this up sometimes
|
||||
echo "docker build dir: $(pwd)"
|
||||
|
||||
docker build --build-arg DOCKER_TAG=$DOCKER_TAG --build-arg DOCKER_COMMIT=$SOURCE_COMMIT -f $DOCKERFILE_PATH -t $IMAGE_NAME .
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
#!/bin/bash
|
||||
|
||||
# entrypoint for scribe Docker image
|
||||
|
||||
set -euo pipefail
|
||||
|
||||
if [ -z "$HUB_COMMAND" ]; then
|
||||
echo "HUB_COMMAND env variable must be scribe, scribe-hub, or scribe-elastic-sync"
|
||||
exit 1
|
||||
fi
|
||||
|
||||
case "$HUB_COMMAND" in
|
||||
scribe ) exec /home/lbry/.local/bin/scribe "$@" ;;
|
||||
scribe-hub ) exec /home/lbry/.local/bin/scribe-hub "$@" ;;
|
||||
scribe-elastic-sync ) exec /home/lbry/.local/bin/scribe-elastic-sync ;;
|
||||
* ) "HUB_COMMAND env variable must be scribe, scribe-hub, or scribe-elastic-sync" && exit 1 ;;
|
||||
esac
|
||||
23
docs/blocking.md
Normal file
23
docs/blocking.md
Normal file
|
|
@ -0,0 +1,23 @@
|
|||
### Claim filtering and blocking
|
||||
|
||||
- Filtered claims are removed from claim search results (`blockchain.claimtrie.search`), they can still be resolved (`blockchain.claimtrie.resolve`)
|
||||
- Blocked claims are not included in claim search results and cannot be resolved.
|
||||
|
||||
Claims that are either filtered or blocked are replaced with a corresponding error message that includes the censoring channel id in a result that would return them.
|
||||
|
||||
#### How to filter or block claims:
|
||||
1. Make a channel (using lbry-sdk) and include the claim id of the channel in `--filtering_channel_ids` or `--blocking_channel_ids` used by `scribe-hub` **and** `scribe-elastic-sync`, depending on which you want to use the channel for. To use both blocking and filtering, make one channel for each.
|
||||
2. Using lbry-sdk, repost the claim to be blocked or filtered using your corresponding channel. If you block/filter a claim id for a channel, it will block/filter all of the claims in the channel.
|
||||
|
||||
#### Defaults
|
||||
|
||||
The example docker-composes in the setup guide use the following defaults:
|
||||
|
||||
Filtering:
|
||||
- `lbry://@LBRY-TagAbuse#770bd7ecba84fd2f7607fb15aedd2b172c2e153f`
|
||||
- `lbry://@LBRY-UntaggedPorn#95e5db68a3101df19763f3a5182e4b12ba393ee8`
|
||||
|
||||
Blocking
|
||||
- `lbry://@LBRY-DMCA#dd687b357950f6f271999971f43c785e8067c3a9`
|
||||
- `lbry://@LBRY-DMCARedFlag#06871aa438032244202840ec59a469b303257cad`
|
||||
- `lbry://@LBRY-OtherUSIllegal#b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6`
|
||||
201
docs/cluster_guide.md
Normal file
201
docs/cluster_guide.md
Normal file
|
|
@ -0,0 +1,201 @@
|
|||
## Cluster environment guide
|
||||
|
||||
For best performance the recommended setup uses three server instances, these can be rented VPSs, self hosted VMs (ideally not on one physical host unless the host is sufficiently powerful), or physical computers. One is a dedicated lbcd node, one an elasticsearch server, and the third runs the hub services (scribe, herald, and scribe-elastic-sync). With this configuration the lbcd and elasticsearch servers can be shared between multiple herald servers - more on that later.
|
||||
Server Requirements (space requirements are at least double what's needed so it's possible to copy snapshots into place or make snapshots):
|
||||
- lbcd: 2 cores, 8gb ram (slightly more may be required syncing from scratch, from a snapshot 8 is plenty), 150gb of NVMe storage
|
||||
- elasticsearch: 8 cores, 9gb of ram (8gb minimum given to ES), 150gb of SSD speed storage
|
||||
- hub: 8 cores, 32gb of ram, 200gb of NVMe storage
|
||||
|
||||
All servers are assumed to be running ubuntu 20.04 with user named `lbry` with passwordless sudo and docker group permissions, ssh configured, ulimits set high (in `/etc/security/limits.conf`, also see [this](https://unix.stackexchange.com/questions/366352/etc-security-limits-conf-not-applied/370652#370652) if the ulimit won't apply), and docker + docker-compose installed. The server running elasticsearch should have swap disabled. The three servers need to be able to communicate with each other, they can be on a local network together or communicate over the internet. This guide will assume the three servers are on the internet.
|
||||
|
||||
### Setting up the lbcd instance
|
||||
Log in to the lbcd instance and perform the following steps:
|
||||
- Build the lbcd docker image by running
|
||||
```
|
||||
git clone https://github.com/lbryio/lbcd.git
|
||||
cd lbcd
|
||||
docker build . -t lbry/lbcd:latest
|
||||
```
|
||||
- Copy the following to `~/docker-compose.yml`
|
||||
```
|
||||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbcd:
|
||||
|
||||
services:
|
||||
lbcd:
|
||||
image: lbry/lbcd:latest
|
||||
restart: always
|
||||
network_mode: host
|
||||
command:
|
||||
- "--notls"
|
||||
- "--rpcuser=lbry"
|
||||
- "--rpcpass=lbry"
|
||||
- "--rpclisten=127.0.0.1"
|
||||
volumes:
|
||||
- "lbcd:/root/.lbcd"
|
||||
ports:
|
||||
- "127.0.0.1:9245:9245"
|
||||
- "9246:9246" # p2p port
|
||||
```
|
||||
- Start lbcd by running `docker-compose up -d`
|
||||
- Check the progress with `docker-compose logs -f --tail 100`
|
||||
|
||||
### Setting up the elasticsearch instance
|
||||
Log in to the elasticsearch instance and perform the following steps:
|
||||
- Copy the following to `~/docker-compose.yml`
|
||||
```
|
||||
version: "3"
|
||||
|
||||
volumes:
|
||||
es01:
|
||||
|
||||
services:
|
||||
es01:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.16.0
|
||||
container_name: es01
|
||||
environment:
|
||||
- node.name=es01
|
||||
- discovery.type=single-node
|
||||
- indices.query.bool.max_clause_count=8192
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms8g -Xmx8g" # no more than 32, remember to disable swap
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- "es01:/usr/share/elasticsearch/data"
|
||||
ports:
|
||||
- "127.0.0.1:9200:9200"
|
||||
```
|
||||
- Start elasticsearch by running `docker-compose up -d`
|
||||
- Check the status with `docker-compose logs -f --tail 100`
|
||||
|
||||
### Setting up the hub instance
|
||||
- Log in (ssh) to the hub instance and generate and print out a ssh key, this is needed to set up port forwards to the other two instances. Copy the output of the following:
|
||||
```
|
||||
ssh-keygen -q -t ed25519 -N '' -f ~/.ssh/id_ed25519 <<<y >/dev/null 2>&1
|
||||
```
|
||||
- After copying the above key, log out of the hub instance.
|
||||
|
||||
- Log in to the elasticsearch instance add the copied key to `~/.ssh/authorized_keys` (see [this](https://stackoverflow.com/questions/6377009/adding-a-public-key-to-ssh-authorized-keys-does-not-log-me-in-automatically) if confused). Log out of the elasticsearch instance once done.
|
||||
- Log in to the lbcd instance and add the copied key to `~/.ssh/authorized_keys`, log out when done.
|
||||
- Log in to the hub instance and copy the following to `/etc/systemd/system/es-tunnel.service`, replacing `lbry` with your user and `your-elastic-ip` with your elasticsearch instance ip.
|
||||
```
|
||||
[Unit]
|
||||
Description=Persistent SSH Tunnel for ES
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
Restart=on-failure
|
||||
RestartSec=5
|
||||
ExecStart=/usr/bin/ssh -NTC -o ServerAliveInterval=60 -o ExitOnForwardFailure=yes -L 127.0.0.1:9200:127.0.0.1:9200 lbry@your-elastic-ip
|
||||
User=lbry
|
||||
Group=lbry
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
- Next, copy the following to `/etc/systemd/system/lbcd-tunnel.service` on the hub instance, replacing `lbry` with your user and `your-lbcd-ip` with your lbcd instance ip.
|
||||
```
|
||||
[Unit]
|
||||
Description=Persistent SSH Tunnel for lbcd
|
||||
After=network.target
|
||||
|
||||
[Service]
|
||||
Restart=on-failure
|
||||
RestartSec=5
|
||||
ExecStart=/usr/bin/ssh -NTC -o ServerAliveInterval=60 -o ExitOnForwardFailure=yes -L 127.0.0.1:9245:127.0.0.1:9245 lbry@your-lbcd-ip
|
||||
User=lbry
|
||||
Group=lbry
|
||||
|
||||
[Install]
|
||||
WantedBy=multi-user.target
|
||||
```
|
||||
- Verify you can ssh in to the elasticsearch and lbcd instances from the hub instance
|
||||
- Enable and start the ssh port forward services on the hub instance
|
||||
```
|
||||
sudo systemctl enable es-tunnel.service
|
||||
sudo systemctl enable lbcd-tunnel.service
|
||||
sudo systemctl start es-tunnel.service
|
||||
sudo systemctl start lbcd-tunnel.service
|
||||
```
|
||||
- Build the hub docker image on the hub instance by running the following:
|
||||
```
|
||||
git clone https://github.com/lbryio/hub.git
|
||||
cd hub
|
||||
docker build -t lbry/hub:development .
|
||||
```
|
||||
- Copy the following to `~/docker-compose.yml` on the hub instance
|
||||
```
|
||||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbry_rocksdb:
|
||||
|
||||
services:
|
||||
scribe:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe
|
||||
- SNAPSHOT_URL=https://snapshots.lbry.com/hub/lbry-rocksdb.zip
|
||||
command:
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--max_query_workers=2"
|
||||
- "--cache_all_tx_hashes"
|
||||
- "--index_address_statuses"
|
||||
scribe_elastic_sync:
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "127.0.0.1:19080:19080" # elastic notifier port
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe-elastic-sync
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6
|
||||
command:
|
||||
- "--elastic_host=127.0.0.1"
|
||||
- "--elastic_port=9200"
|
||||
- "--max_query_workers=2"
|
||||
herald:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
- scribe
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "50001:50001" # electrum rpc port and udp ping port
|
||||
- "2112:2112" # comment out to disable prometheus metrics
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=herald
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6
|
||||
command:
|
||||
- "--index_address_statuses"
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--elastic_host=127.0.0.1"
|
||||
- "--elastic_port=9200"
|
||||
- "--max_query_workers=4"
|
||||
- "--host=0.0.0.0"
|
||||
- "--max_sessions=100000"
|
||||
- "--prometheus_port=2112" # comment out to disable prometheus metrics
|
||||
```
|
||||
- Start the hub services by running `docker-compose up -d`
|
||||
- Check the status with `docker-compose logs -f --tail 100`
|
||||
|
||||
### Manual setup of docker volumes from snapshots
|
||||
For an example of copying and configuring permissions for a hub docker volume, see [this](https://github.com/lbryio/hub/blob/master/scripts/initialize_rocksdb_snapshot_dev.sh). For an example for the elasticsearch volume, see [this](https://github.com/lbryio/hub/blob/master/scripts/initialize_es_snapshot_dev.sh). **Read these scripts before running them** to avoid overwriting the wrong volume, they are more of a guide on how to set the permissions and where files go than setup scripts.
|
||||
BIN
docs/diagram.png
Normal file
BIN
docs/diagram.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 103 KiB |
99
docs/docker_examples/docker-compose.yml
Normal file
99
docs/docker_examples/docker-compose.yml
Normal file
|
|
@ -0,0 +1,99 @@
|
|||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbcd:
|
||||
lbry_rocksdb:
|
||||
es01:
|
||||
|
||||
services:
|
||||
scribe:
|
||||
depends_on:
|
||||
- lbcd
|
||||
- scribe_elastic_sync
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe
|
||||
- SNAPSHOT_URL=https://snapshots.lbry.com/hub/block_1312050/lbry-rocksdb.tar
|
||||
command: # for full options, see `scribe --help`
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--max_query_workers=2"
|
||||
- "--index_address_statuses"
|
||||
scribe_elastic_sync:
|
||||
depends_on:
|
||||
- es01
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "127.0.0.1:19080:19080" # elastic notifier port
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe-elastic-sync
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8 d4612c256a44fc025c37a875751415299b1f8220
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6 145265bd234b7c9c28dfc6857d878cca402dda94 22335fbb132eee86d374b613875bf88bec83492f f665b89b999f411aa5def311bb2eb385778d49c8
|
||||
command: # for full options, see `scribe-elastic-sync --help`
|
||||
- "--max_query_workers=2"
|
||||
- "--elastic_host=127.0.0.1" # elasticsearch host
|
||||
- "--elastic_port=9200" # elasticsearch port
|
||||
herald:
|
||||
depends_on:
|
||||
- lbcd
|
||||
- scribe_elastic_sync
|
||||
- scribe
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "50001:50001" # electrum rpc port and udp ping port
|
||||
- "2112:2112" # comment out to disable prometheus metrics
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=herald
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8 d4612c256a44fc025c37a875751415299b1f8220
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6 145265bd234b7c9c28dfc6857d878cca402dda94 22335fbb132eee86d374b613875bf88bec83492f f665b89b999f411aa5def311bb2eb385778d49c8
|
||||
command: # for full options, see `herald --help`
|
||||
- "--index_address_statuses"
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--max_query_workers=4"
|
||||
- "--host=0.0.0.0"
|
||||
- "--elastic_services=127.0.0.1:9200/127.0.0.1:19080"
|
||||
- "--prometheus_port=2112" # comment out to disable prometheus metrics
|
||||
# - "--max_sessions=100000 # uncomment to increase the maximum number of electrum connections, defaults to 1000
|
||||
# - "--allow_lan_udp" # uncomment to reply to clients on the local network
|
||||
es01:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.16.0
|
||||
container_name: es01
|
||||
environment:
|
||||
- node.name=es01
|
||||
- discovery.type=single-node
|
||||
- indices.query.bool.max_clause_count=8192
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms8g -Xmx8g" # no more than 32, remember to disable swap
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- "es01:/usr/share/elasticsearch/data"
|
||||
ports:
|
||||
- "127.0.0.1:9200:9200"
|
||||
lbcd:
|
||||
image: lbry/lbcd:latest
|
||||
restart: always
|
||||
network_mode: host
|
||||
command:
|
||||
- "--notls"
|
||||
- "--listen=0.0.0.0:9246"
|
||||
- "--rpclisten=127.0.0.1:9245"
|
||||
- "--rpcuser=lbry"
|
||||
- "--rpcpass=lbry"
|
||||
volumes:
|
||||
- "lbcd:/root/.lbcd"
|
||||
ports:
|
||||
- "9246:9246" # p2p
|
||||
23
docs/docker_examples/elastic-compose.yml
Normal file
23
docs/docker_examples/elastic-compose.yml
Normal file
|
|
@ -0,0 +1,23 @@
|
|||
version: "3"
|
||||
|
||||
volumes:
|
||||
es01:
|
||||
|
||||
services:
|
||||
es01:
|
||||
image: docker.elastic.co/elasticsearch/elasticsearch:7.16.0
|
||||
container_name: es01
|
||||
environment:
|
||||
- node.name=es01
|
||||
- discovery.type=single-node
|
||||
- indices.query.bool.max_clause_count=8192
|
||||
- bootstrap.memory_lock=true
|
||||
- "ES_JAVA_OPTS=-Dlog4j2.formatMsgNoLookups=true -Xms8g -Xmx8g" # no more than 32, remember to disable swap
|
||||
ulimits:
|
||||
memlock:
|
||||
soft: -1
|
||||
hard: -1
|
||||
volumes:
|
||||
- "es01:/usr/share/elasticsearch/data"
|
||||
ports:
|
||||
- "127.0.0.1:9200:9200"
|
||||
59
docs/docker_examples/hub-compose.yml
Normal file
59
docs/docker_examples/hub-compose.yml
Normal file
|
|
@ -0,0 +1,59 @@
|
|||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbry_rocksdb:
|
||||
|
||||
services:
|
||||
scribe:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe
|
||||
- SNAPSHOT_URL=https://snapshots.lbry.com/hub/block_1312050/lbry-rocksdb.tar
|
||||
command:
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--max_query_workers=2"
|
||||
scribe_elastic_sync:
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "127.0.0.1:19080:19080" # elastic notifier port
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=scribe-elastic-sync
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8 d4612c256a44fc025c37a875751415299b1f8220
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6 145265bd234b7c9c28dfc6857d878cca402dda94 22335fbb132eee86d374b613875bf88bec83492f f665b89b999f411aa5def311bb2eb385778d49c8
|
||||
command:
|
||||
- "--elastic_host=127.0.0.1"
|
||||
- "--elastic_port=9200"
|
||||
- "--max_query_workers=2"
|
||||
herald:
|
||||
depends_on:
|
||||
- scribe_elastic_sync
|
||||
- scribe
|
||||
image: lbry/hub:${SCRIBE_TAG:-master}
|
||||
restart: always
|
||||
network_mode: host
|
||||
ports:
|
||||
- "50001:50001" # electrum rpc port and udp ping port
|
||||
- "2112:2112" # comment out to disable prometheus metrics
|
||||
volumes:
|
||||
- "lbry_rocksdb:/database"
|
||||
environment:
|
||||
- HUB_COMMAND=herald
|
||||
- FILTERING_CHANNEL_IDS=770bd7ecba84fd2f7607fb15aedd2b172c2e153f 95e5db68a3101df19763f3a5182e4b12ba393ee8 d4612c256a44fc025c37a875751415299b1f8220
|
||||
- BLOCKING_CHANNEL_IDS=dd687b357950f6f271999971f43c785e8067c3a9 06871aa438032244202840ec59a469b303257cad b4a2528f436eca1bf3bf3e10ff3f98c57bd6c4c6 145265bd234b7c9c28dfc6857d878cca402dda94 22335fbb132eee86d374b613875bf88bec83492f f665b89b999f411aa5def311bb2eb385778d49c8
|
||||
command:
|
||||
- "--daemon_url=http://lbry:lbry@127.0.0.1:9245"
|
||||
- "--elastic_services=127.0.0.1:9200/127.0.0.1:19080"
|
||||
- "--max_query_workers=4"
|
||||
- "--host=0.0.0.0"
|
||||
- "--max_sessions=100000"
|
||||
- "--prometheus_port=2112" # comment out to disable prometheus metrics
|
||||
19
docs/docker_examples/lbcd-compose.yml
Normal file
19
docs/docker_examples/lbcd-compose.yml
Normal file
|
|
@ -0,0 +1,19 @@
|
|||
version: "3"
|
||||
|
||||
volumes:
|
||||
lbcd:
|
||||
|
||||
services:
|
||||
lbcd:
|
||||
image: lbry/lbcd:latest
|
||||
restart: always
|
||||
network_mode: host
|
||||
command:
|
||||
- "--rpcuser=lbry"
|
||||
- "--rpcpass=lbry"
|
||||
- "--rpclisten=127.0.0.1"
|
||||
volumes:
|
||||
- "lbcd:/root/.lbcd"
|
||||
ports:
|
||||
- "127.0.0.1:9245:9245"
|
||||
- "9246:9246" # p2p port
|
||||
1101
hub/common.py
Normal file
1101
hub/common.py
Normal file
File diff suppressed because it is too large
Load diff
1
hub/db/__init__.py
Normal file
1
hub/db/__init__.py
Normal file
|
|
@ -0,0 +1 @@
|
|||
from .db import SecondaryDB
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
import typing
|
||||
import enum
|
||||
from typing import Optional
|
||||
from scribe.error import ResolveCensoredError
|
||||
from hub.error import ResolveCensoredError
|
||||
|
||||
|
||||
@enum.unique
|
||||
|
|
@ -16,7 +16,7 @@ class DB_PREFIXES(enum.Enum):
|
|||
channel_to_claim = b'J'
|
||||
|
||||
claim_short_id_prefix = b'F'
|
||||
effective_amount = b'D'
|
||||
bid_order = b'D'
|
||||
claim_expiration = b'O'
|
||||
|
||||
claim_takeover = b'P'
|
||||
|
|
@ -48,27 +48,15 @@ class DB_PREFIXES(enum.Enum):
|
|||
touched_hashX = b'e'
|
||||
hashX_status = b'f'
|
||||
hashX_mempool_status = b'g'
|
||||
reposted_count = b'j'
|
||||
effective_amount = b'i'
|
||||
future_effective_amount = b'k'
|
||||
hashX_history_hash = b'l'
|
||||
|
||||
|
||||
COLUMN_SETTINGS = {} # this is updated by the PrefixRow metaclass
|
||||
|
||||
|
||||
CLAIM_TYPES = {
|
||||
'stream': 1,
|
||||
'channel': 2,
|
||||
'repost': 3,
|
||||
'collection': 4,
|
||||
}
|
||||
|
||||
STREAM_TYPES = {
|
||||
'video': 1,
|
||||
'audio': 2,
|
||||
'image': 3,
|
||||
'document': 4,
|
||||
'binary': 5,
|
||||
'model': 6,
|
||||
}
|
||||
|
||||
# 9/21/2020
|
||||
MOST_USED_TAGS = {
|
||||
"gaming",
|
||||
1432
hub/db/db.py
Normal file
1432
hub/db/db.py
Normal file
File diff suppressed because it is too large
Load diff
|
|
@ -1,9 +1,10 @@
|
|||
import asyncio
|
||||
import struct
|
||||
import typing
|
||||
import rocksdb
|
||||
from typing import Optional
|
||||
from scribe.db.common import DB_PREFIXES, COLUMN_SETTINGS
|
||||
from scribe.db.revertable import RevertableOpStack, RevertablePut, RevertableDelete
|
||||
from hub.db.common import DB_PREFIXES, COLUMN_SETTINGS
|
||||
from hub.db.revertable import RevertableOpStack, RevertablePut, RevertableDelete
|
||||
|
||||
|
||||
ROW_TYPES = {}
|
||||
|
|
@ -88,6 +89,12 @@ class PrefixRow(metaclass=PrefixRowType):
|
|||
if v:
|
||||
return v if not deserialize_value else self.unpack_value(v)
|
||||
|
||||
def key_exists(self, *key_args):
|
||||
key_may_exist, _ = self._db.key_may_exist((self._column_family, self.pack_key(*key_args)))
|
||||
if not key_may_exist:
|
||||
return False
|
||||
return self._db.get((self._column_family, self.pack_key(*key_args)), fill_cache=True) is not None
|
||||
|
||||
def multi_get(self, key_args: typing.List[typing.Tuple], fill_cache=True, deserialize_value=True):
|
||||
packed_keys = {tuple(args): self.pack_key(*args) for args in key_args}
|
||||
db_result = self._db.multi_get([(self._column_family, packed_keys[tuple(args)]) for args in key_args],
|
||||
|
|
@ -101,23 +108,44 @@ class PrefixRow(metaclass=PrefixRowType):
|
|||
handle_value(result[packed_keys[tuple(k_args)]]) for k_args in key_args
|
||||
]
|
||||
|
||||
async def multi_get_async_gen(self, executor, key_args: typing.List[typing.Tuple], deserialize_value=True, step=1000):
|
||||
packed_keys = {self.pack_key(*args): args for args in key_args}
|
||||
assert len(packed_keys) == len(key_args), 'duplicate partial keys given to multi_get_dict'
|
||||
db_result = await asyncio.get_event_loop().run_in_executor(
|
||||
executor, self._db.multi_get, [(self._column_family, key) for key in packed_keys]
|
||||
)
|
||||
unpack_value = self.unpack_value
|
||||
|
||||
def handle_value(v):
|
||||
return None if v is None else v if not deserialize_value else unpack_value(v)
|
||||
|
||||
for idx, (k, v) in enumerate((db_result or {}).items()):
|
||||
yield (packed_keys[k[-1]], handle_value(v))
|
||||
if idx % step == 0:
|
||||
await asyncio.sleep(0)
|
||||
|
||||
def stash_multi_put(self, items):
|
||||
self._op_stack.stash_ops([RevertablePut(self.pack_key(*k), self.pack_value(*v)) for k, v in items])
|
||||
|
||||
def stash_multi_delete(self, items):
|
||||
self._op_stack.stash_ops([RevertableDelete(self.pack_key(*k), self.pack_value(*v)) for k, v in items])
|
||||
|
||||
def get_pending(self, *key_args, fill_cache=True, deserialize_value=True):
|
||||
packed_key = self.pack_key(*key_args)
|
||||
last_op = self._op_stack.get_last_op_for_key(packed_key)
|
||||
if last_op:
|
||||
if last_op.is_put:
|
||||
return last_op.value if not deserialize_value else self.unpack_value(last_op.value)
|
||||
else: # it's a delete
|
||||
return
|
||||
v = self._db.get((self._column_family, packed_key), fill_cache=fill_cache)
|
||||
if v:
|
||||
return v if not deserialize_value else self.unpack_value(v)
|
||||
pending_op = self._op_stack.get_pending_op(packed_key)
|
||||
if pending_op and pending_op.is_delete:
|
||||
return
|
||||
if pending_op:
|
||||
v = pending_op.value
|
||||
else:
|
||||
v = self._db.get((self._column_family, packed_key), fill_cache=fill_cache)
|
||||
return None if v is None else (v if not deserialize_value else self.unpack_value(v))
|
||||
|
||||
def stage_put(self, key_args=(), value_args=()):
|
||||
self._op_stack.append_op(RevertablePut(self.pack_key(*key_args), self.pack_value(*value_args)))
|
||||
def stash_put(self, key_args=(), value_args=()):
|
||||
self._op_stack.stash_ops([RevertablePut(self.pack_key(*key_args), self.pack_value(*value_args))])
|
||||
|
||||
def stage_delete(self, key_args=(), value_args=()):
|
||||
self._op_stack.append_op(RevertableDelete(self.pack_key(*key_args), self.pack_value(*value_args)))
|
||||
def stash_delete(self, key_args=(), value_args=()):
|
||||
self._op_stack.stash_ops([RevertableDelete(self.pack_key(*key_args), self.pack_value(*value_args))])
|
||||
|
||||
@classmethod
|
||||
def pack_partial_key(cls, *args) -> bytes:
|
||||
|
|
@ -155,13 +183,14 @@ class BasePrefixDB:
|
|||
UNDO_KEY_STRUCT = struct.Struct(b'>Q32s')
|
||||
PARTIAL_UNDO_KEY_STRUCT = struct.Struct(b'>Q')
|
||||
|
||||
def __init__(self, path, max_open_files=64, secondary_path='', max_undo_depth: int = 200, unsafe_prefixes=None):
|
||||
def __init__(self, path, max_open_files=64, secondary_path='', max_undo_depth: int = 200, unsafe_prefixes=None,
|
||||
enforce_integrity=True):
|
||||
column_family_options = {}
|
||||
for prefix in DB_PREFIXES:
|
||||
settings = COLUMN_SETTINGS[prefix.value]
|
||||
column_family_options[prefix.value] = rocksdb.ColumnFamilyOptions()
|
||||
column_family_options[prefix.value].table_factory = rocksdb.BlockBasedTableFactory(
|
||||
block_cache=rocksdb.LRUCache(settings['cache_size']),
|
||||
block_cache=rocksdb.LRUCache(settings['cache_size'])
|
||||
)
|
||||
self.column_families: typing.Dict[bytes, 'rocksdb.ColumnFamilyHandle'] = {}
|
||||
options = rocksdb.Options(
|
||||
|
|
@ -178,7 +207,9 @@ class BasePrefixDB:
|
|||
cf = self._db.get_column_family(prefix.value)
|
||||
self.column_families[prefix.value] = cf
|
||||
|
||||
self._op_stack = RevertableOpStack(self.get, unsafe_prefixes=unsafe_prefixes)
|
||||
self._op_stack = RevertableOpStack(
|
||||
self.get, self.multi_get, unsafe_prefixes=unsafe_prefixes, enforce_integrity=enforce_integrity
|
||||
)
|
||||
self._max_undo_depth = max_undo_depth
|
||||
|
||||
def unsafe_commit(self):
|
||||
|
|
@ -186,6 +217,7 @@ class BasePrefixDB:
|
|||
Write staged changes to the database without keeping undo information
|
||||
Changes written cannot be undone
|
||||
"""
|
||||
self.apply_stash()
|
||||
try:
|
||||
if not len(self._op_stack):
|
||||
return
|
||||
|
|
@ -206,6 +238,7 @@ class BasePrefixDB:
|
|||
"""
|
||||
Write changes for a block height to the database and keep undo information so that the changes can be reverted
|
||||
"""
|
||||
self.apply_stash()
|
||||
undo_ops = self._op_stack.get_undo_ops()
|
||||
delete_undos = []
|
||||
if height > self._max_undo_depth:
|
||||
|
|
@ -240,6 +273,7 @@ class BasePrefixDB:
|
|||
undo_c_f = self.column_families[DB_PREFIXES.undo.value]
|
||||
undo_info = self._db.get((undo_c_f, undo_key))
|
||||
self._op_stack.apply_packed_undo_ops(undo_info)
|
||||
self._op_stack.validate_and_apply_stashed_ops()
|
||||
try:
|
||||
with self._db.write_batch(sync=True) as batch:
|
||||
batch_put = batch.put
|
||||
|
|
@ -255,10 +289,26 @@ class BasePrefixDB:
|
|||
finally:
|
||||
self._op_stack.clear()
|
||||
|
||||
def apply_stash(self):
|
||||
self._op_stack.validate_and_apply_stashed_ops()
|
||||
|
||||
def get(self, key: bytes, fill_cache: bool = True) -> Optional[bytes]:
|
||||
cf = self.column_families[key[:1]]
|
||||
return self._db.get((cf, key), fill_cache=fill_cache)
|
||||
|
||||
def multi_get(self, keys: typing.List[bytes], fill_cache=True):
|
||||
if len(keys) == 0:
|
||||
return []
|
||||
get_cf = self.column_families.__getitem__
|
||||
db_result = self._db.multi_get([(get_cf(k[:1]), k) for k in keys], fill_cache=fill_cache)
|
||||
return list(db_result.values())
|
||||
|
||||
def multi_delete(self, items: typing.List[typing.Tuple[bytes, bytes]]):
|
||||
self._op_stack.stash_ops([RevertableDelete(k, v) for k, v in items])
|
||||
|
||||
def multi_put(self, items: typing.List[typing.Tuple[bytes, bytes]]):
|
||||
self._op_stack.stash_ops([RevertablePut(k, v) for k, v in items])
|
||||
|
||||
def iterator(self, start: bytes, column_family: 'rocksdb.ColumnFamilyHandle' = None,
|
||||
iterate_lower_bound: bytes = None, iterate_upper_bound: bytes = None,
|
||||
reverse: bool = False, include_key: bool = True, include_value: bool = True,
|
||||
|
|
@ -276,11 +326,11 @@ class BasePrefixDB:
|
|||
def try_catch_up_with_primary(self):
|
||||
self._db.try_catch_up_with_primary()
|
||||
|
||||
def stage_raw_put(self, key: bytes, value: bytes):
|
||||
self._op_stack.append_op(RevertablePut(key, value))
|
||||
def stash_raw_put(self, key: bytes, value: bytes):
|
||||
self._op_stack.stash_ops([RevertablePut(key, value)])
|
||||
|
||||
def stage_raw_delete(self, key: bytes, value: bytes):
|
||||
self._op_stack.append_op(RevertableDelete(key, value))
|
||||
def stash_raw_delete(self, key: bytes, value: bytes):
|
||||
self._op_stack.stash_ops([RevertableDelete(key, value)])
|
||||
|
||||
def estimate_num_keys(self, column_family: 'rocksdb.ColumnFamilyHandle' = None):
|
||||
return int(self._db.get_property(b'rocksdb.estimate-num-keys', column_family).decode())
|
||||
|
|
@ -29,7 +29,7 @@ import typing
|
|||
from asyncio import Event
|
||||
from math import ceil, log
|
||||
|
||||
from scribe.common import double_sha256
|
||||
from hub.common import double_sha256
|
||||
|
||||
|
||||
class Merkle:
|
||||
67
hub/db/migrators/migrate10to11.py
Normal file
67
hub/db/migrators/migrate10to11.py
Normal file
|
|
@ -0,0 +1,67 @@
|
|||
import logging
|
||||
from collections import defaultdict
|
||||
from hub.db.prefixes import ACTIVATED_SUPPORT_TXO_TYPE
|
||||
|
||||
FROM_VERSION = 10
|
||||
TO_VERSION = 11
|
||||
|
||||
|
||||
def migrate(db):
|
||||
log = logging.getLogger(__name__)
|
||||
prefix_db = db.prefix_db
|
||||
|
||||
log.info("migrating the db to version 11")
|
||||
|
||||
effective_amounts = defaultdict(int)
|
||||
support_amounts = defaultdict(int)
|
||||
|
||||
log.info("deleting any existing effective amounts")
|
||||
|
||||
to_delete = list(prefix_db.effective_amount.iterate(deserialize_key=False, deserialize_value=False))
|
||||
while to_delete:
|
||||
batch, to_delete = to_delete[:100000], to_delete[100000:]
|
||||
if batch:
|
||||
prefix_db.multi_delete(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
|
||||
log.info("calculating claim effective amounts for the new index at block %i", db.db_height)
|
||||
|
||||
height = db.db_height
|
||||
|
||||
cnt = 0
|
||||
for k, v in prefix_db.active_amount.iterate():
|
||||
cnt += 1
|
||||
claim_hash, activation_height, amount = k.claim_hash, k.activation_height, v.amount
|
||||
if activation_height <= height:
|
||||
effective_amounts[claim_hash] += amount
|
||||
if k.txo_type == ACTIVATED_SUPPORT_TXO_TYPE:
|
||||
support_amounts[claim_hash] += amount
|
||||
if cnt % 1000000 == 0:
|
||||
log.info("scanned %i amounts for %i claims", cnt, len(effective_amounts))
|
||||
|
||||
log.info("preparing to insert effective amounts")
|
||||
|
||||
effective_amounts_to_put = [
|
||||
prefix_db.effective_amount.pack_item(claim_hash, effective_amount, support_amounts[claim_hash])
|
||||
for claim_hash, effective_amount in effective_amounts.items()
|
||||
]
|
||||
|
||||
log.info("inserting %i effective amounts", len(effective_amounts_to_put))
|
||||
|
||||
cnt = 0
|
||||
|
||||
while effective_amounts_to_put:
|
||||
batch, effective_amounts_to_put = effective_amounts_to_put[:100000], effective_amounts_to_put[100000:]
|
||||
if batch:
|
||||
prefix_db.multi_put(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
cnt += len(batch)
|
||||
if cnt % 1000000 == 0:
|
||||
log.info("inserted effective amounts for %i claims", cnt)
|
||||
|
||||
log.info("finished building the effective amount index")
|
||||
|
||||
db.db_version = 11
|
||||
db.write_db_state()
|
||||
db.prefix_db.unsafe_commit()
|
||||
log.info("finished migration to version 11")
|
||||
57
hub/db/migrators/migrate11to12.py
Normal file
57
hub/db/migrators/migrate11to12.py
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
import logging
|
||||
from collections import defaultdict
|
||||
|
||||
FROM_VERSION = 11
|
||||
TO_VERSION = 12
|
||||
|
||||
|
||||
def migrate(db):
|
||||
log = logging.getLogger(__name__)
|
||||
prefix_db = db.prefix_db
|
||||
|
||||
log.info("migrating the db to version 12")
|
||||
|
||||
effective_amounts = defaultdict(int)
|
||||
|
||||
log.info("deleting any existing future effective amounts")
|
||||
|
||||
to_delete = list(prefix_db.future_effective_amount.iterate(deserialize_key=False, deserialize_value=False))
|
||||
while to_delete:
|
||||
batch, to_delete = to_delete[:100000], to_delete[100000:]
|
||||
if batch:
|
||||
prefix_db.multi_delete(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
|
||||
log.info("calculating future claim effective amounts for the new index at block %i", db.db_height)
|
||||
cnt = 0
|
||||
for k, v in prefix_db.active_amount.iterate():
|
||||
cnt += 1
|
||||
effective_amounts[k.claim_hash] += v.amount
|
||||
if cnt % 1000000 == 0:
|
||||
log.info("scanned %i amounts for %i claims", cnt, len(effective_amounts))
|
||||
log.info("preparing to insert future effective amounts")
|
||||
|
||||
effective_amounts_to_put = [
|
||||
prefix_db.future_effective_amount.pack_item(claim_hash, effective_amount)
|
||||
for claim_hash, effective_amount in effective_amounts.items()
|
||||
]
|
||||
|
||||
log.info("inserting %i future effective amounts", len(effective_amounts_to_put))
|
||||
|
||||
cnt = 0
|
||||
|
||||
while effective_amounts_to_put:
|
||||
batch, effective_amounts_to_put = effective_amounts_to_put[:100000], effective_amounts_to_put[100000:]
|
||||
if batch:
|
||||
prefix_db.multi_put(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
cnt += len(batch)
|
||||
if cnt % 1000000 == 0:
|
||||
log.info("inserted effective amounts for %i claims", cnt)
|
||||
|
||||
log.info("finished building the effective amount index")
|
||||
|
||||
db.db_version = 12
|
||||
db.write_db_state()
|
||||
db.prefix_db.unsafe_commit()
|
||||
log.info("finished migration to version 12")
|
||||
|
|
@ -3,9 +3,9 @@ import time
|
|||
import array
|
||||
import typing
|
||||
from bisect import bisect_right
|
||||
from scribe.common import sha256
|
||||
from hub.common import sha256
|
||||
if typing.TYPE_CHECKING:
|
||||
from scribe.db.db import HubDB
|
||||
from hub.scribe.db import PrimaryDB
|
||||
|
||||
FROM_VERSION = 7
|
||||
TO_VERSION = 8
|
||||
|
|
@ -35,7 +35,7 @@ def hashX_history(db: 'HubDB', hashX: bytes):
|
|||
return history, to_delete
|
||||
|
||||
|
||||
def hashX_status_from_history(db: 'HubDB', history: bytes) -> bytes:
|
||||
def hashX_status_from_history(db: 'PrimaryDB', history: bytes) -> bytes:
|
||||
tx_counts = db.tx_counts
|
||||
hist_tx_nums = array.array('I')
|
||||
hist_tx_nums.frombytes(history)
|
||||
26
hub/db/migrators/migrate8to9.py
Normal file
26
hub/db/migrators/migrate8to9.py
Normal file
|
|
@ -0,0 +1,26 @@
|
|||
import logging
|
||||
|
||||
FROM_VERSION = 8
|
||||
TO_VERSION = 9
|
||||
|
||||
|
||||
def migrate(db):
|
||||
log = logging.getLogger(__name__)
|
||||
prefix_db = db.prefix_db
|
||||
index_address_status = db._index_address_status
|
||||
|
||||
log.info("migrating the db to version 9")
|
||||
|
||||
if not index_address_status:
|
||||
log.info("deleting the existing address status index")
|
||||
to_delete = list(prefix_db.hashX_status.iterate(deserialize_key=False, deserialize_value=False))
|
||||
while to_delete:
|
||||
batch, to_delete = to_delete[:10000], to_delete[10000:]
|
||||
if batch:
|
||||
prefix_db.multi_delete(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
|
||||
db.db_version = 9
|
||||
db.write_db_state()
|
||||
db.prefix_db.unsafe_commit()
|
||||
log.info("finished migration")
|
||||
48
hub/db/migrators/migrate9to10.py
Normal file
48
hub/db/migrators/migrate9to10.py
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
import logging
|
||||
from collections import defaultdict
|
||||
from hub.db.revertable import RevertablePut
|
||||
|
||||
FROM_VERSION = 9
|
||||
TO_VERSION = 10
|
||||
|
||||
|
||||
def migrate(db):
|
||||
log = logging.getLogger(__name__)
|
||||
prefix_db = db.prefix_db
|
||||
|
||||
log.info("migrating the db to version 10")
|
||||
|
||||
repost_counts = defaultdict(int)
|
||||
log.info("deleting any existing repost counts")
|
||||
|
||||
to_delete = list(prefix_db.reposted_count.iterate(deserialize_key=False, deserialize_value=False))
|
||||
while to_delete:
|
||||
batch, to_delete = to_delete[:10000], to_delete[10000:]
|
||||
if batch:
|
||||
prefix_db.multi_delete(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
|
||||
log.info("counting reposts to build the new index")
|
||||
|
||||
for reposted_claim_hash in prefix_db.repost.iterate(include_key=False, deserialize_value=False):
|
||||
repost_counts[reposted_claim_hash] += 1
|
||||
|
||||
log.info("inserting repost counts")
|
||||
|
||||
reposted_counts_to_put = [
|
||||
prefix_db.reposted_count.pack_item(claim_hash, count)
|
||||
for claim_hash, count in repost_counts.items()
|
||||
]
|
||||
|
||||
while reposted_counts_to_put:
|
||||
batch, reposted_counts_to_put = reposted_counts_to_put[:10000], reposted_counts_to_put[10000:]
|
||||
if batch:
|
||||
prefix_db.multi_put(batch)
|
||||
prefix_db.unsafe_commit()
|
||||
|
||||
log.info("finished building the repost count index")
|
||||
|
||||
db.db_version = 10
|
||||
db.write_db_state()
|
||||
db.prefix_db.unsafe_commit()
|
||||
log.info("finished migration to version 10")
|
||||
|
|
@ -3,9 +3,10 @@ import struct
|
|||
import array
|
||||
import base64
|
||||
from typing import Union, Tuple, NamedTuple, Optional
|
||||
from scribe.db.common import DB_PREFIXES
|
||||
from scribe.db.interface import BasePrefixDB, ROW_TYPES, PrefixRow
|
||||
from scribe.schema.url import normalize_name
|
||||
from hub.common import ResumableSHA256
|
||||
from hub.db.common import DB_PREFIXES
|
||||
from hub.db.interface import BasePrefixDB, ROW_TYPES, PrefixRow
|
||||
from hub.schema.url import normalize_name
|
||||
|
||||
ACTIVATED_CLAIM_TXO_TYPE = 1
|
||||
ACTIVATED_SUPPORT_TXO_TYPE = 2
|
||||
|
|
@ -58,7 +59,7 @@ class HashXHistoryKey(NamedTuple):
|
|||
|
||||
|
||||
class HashXHistoryValue(NamedTuple):
|
||||
hashXes: typing.List[int]
|
||||
tx_nums: typing.List[int]
|
||||
|
||||
|
||||
class BlockHashKey(NamedTuple):
|
||||
|
|
@ -354,14 +355,14 @@ class ActiveAmountValue(typing.NamedTuple):
|
|||
amount: int
|
||||
|
||||
|
||||
class EffectiveAmountKey(typing.NamedTuple):
|
||||
class BidOrderKey(typing.NamedTuple):
|
||||
normalized_name: str
|
||||
effective_amount: int
|
||||
tx_num: int
|
||||
position: int
|
||||
|
||||
|
||||
class EffectiveAmountValue(typing.NamedTuple):
|
||||
class BidOrderValue(typing.NamedTuple):
|
||||
claim_hash: bytes
|
||||
|
||||
def __str__(self):
|
||||
|
|
@ -420,12 +421,40 @@ class DBState(typing.NamedTuple):
|
|||
tip: bytes
|
||||
utxo_flush_count: int
|
||||
wall_time: int
|
||||
catching_up: bool
|
||||
bit_fields: int
|
||||
db_version: int
|
||||
hist_flush_count: int
|
||||
comp_flush_count: int
|
||||
comp_cursor: int
|
||||
es_sync_height: int
|
||||
hashX_status_last_indexed_height: int
|
||||
|
||||
@property
|
||||
def catching_up(self) -> bool:
|
||||
return self.bit_fields & 1 != 0
|
||||
|
||||
@property
|
||||
def index_address_statuses(self) -> bool:
|
||||
return self.bit_fields & 2 != 0
|
||||
|
||||
@property
|
||||
def expanded(self):
|
||||
return (
|
||||
self.genesis,
|
||||
self.height,
|
||||
self.tx_count,
|
||||
self.tip,
|
||||
self.utxo_flush_count,
|
||||
self.wall_time,
|
||||
self.catching_up,
|
||||
self.index_address_statuses,
|
||||
self.db_version,
|
||||
self.hist_flush_count,
|
||||
self.comp_flush_count,
|
||||
self.comp_cursor,
|
||||
self.es_sync_height,
|
||||
self.hashX_status_last_indexed_height
|
||||
)
|
||||
|
||||
|
||||
class ActiveAmountPrefixRow(PrefixRow):
|
||||
|
|
@ -895,8 +924,8 @@ def effective_amount_helper(struct_fmt):
|
|||
return wrapper
|
||||
|
||||
|
||||
class EffectiveAmountPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.effective_amount.value
|
||||
class BidOrderPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.bid_order.value
|
||||
key_struct = struct.Struct(b'>QLH')
|
||||
value_struct = struct.Struct(b'>20s')
|
||||
key_part_lambdas = [
|
||||
|
|
@ -915,16 +944,16 @@ class EffectiveAmountPrefixRow(PrefixRow):
|
|||
)
|
||||
|
||||
@classmethod
|
||||
def unpack_key(cls, key: bytes) -> EffectiveAmountKey:
|
||||
def unpack_key(cls, key: bytes) -> BidOrderKey:
|
||||
assert key[:1] == cls.prefix
|
||||
name_len = int.from_bytes(key[1:3], byteorder='big')
|
||||
name = key[3:3 + name_len].decode()
|
||||
ones_comp_effective_amount, tx_num, position = cls.key_struct.unpack(key[3 + name_len:])
|
||||
return EffectiveAmountKey(name, 0xffffffffffffffff - ones_comp_effective_amount, tx_num, position)
|
||||
return BidOrderKey(name, 0xffffffffffffffff - ones_comp_effective_amount, tx_num, position)
|
||||
|
||||
@classmethod
|
||||
def unpack_value(cls, data: bytes) -> EffectiveAmountValue:
|
||||
return EffectiveAmountValue(*super().unpack_value(data))
|
||||
def unpack_value(cls, data: bytes) -> BidOrderValue:
|
||||
return BidOrderValue(*super().unpack_value(data))
|
||||
|
||||
@classmethod
|
||||
def pack_value(cls, claim_hash: bytes) -> bytes:
|
||||
|
|
@ -997,6 +1026,44 @@ class RepostedPrefixRow(PrefixRow):
|
|||
return cls.pack_key(reposted_claim_hash, tx_num, position), cls.pack_value(claim_hash)
|
||||
|
||||
|
||||
class RepostedCountKey(NamedTuple):
|
||||
claim_hash: bytes
|
||||
|
||||
|
||||
class RepostedCountValue(NamedTuple):
|
||||
reposted_count: int
|
||||
|
||||
|
||||
class RepostedCountPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.reposted_count.value
|
||||
key_struct = struct.Struct(b'>20s')
|
||||
value_struct = struct.Struct(b'>L')
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>20s').pack,
|
||||
]
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, claim_hash: bytes):
|
||||
return super().pack_key(claim_hash)
|
||||
|
||||
@classmethod
|
||||
def unpack_key(cls, key: bytes) -> RepostedCountKey:
|
||||
return RepostedCountKey(*super().unpack_key(key))
|
||||
|
||||
@classmethod
|
||||
def pack_value(cls, reposted_count: int) -> bytes:
|
||||
return super().pack_value(reposted_count)
|
||||
|
||||
@classmethod
|
||||
def unpack_value(cls, data: bytes) -> RepostedCountValue:
|
||||
return RepostedCountValue(*super().unpack_value(data))
|
||||
|
||||
@classmethod
|
||||
def pack_item(cls, claim_hash: bytes, reposted_count: int):
|
||||
return cls.pack_key(claim_hash), cls.pack_value(reposted_count)
|
||||
|
||||
|
||||
class UndoKey(NamedTuple):
|
||||
height: int
|
||||
block_hash: bytes
|
||||
|
|
@ -1104,6 +1171,7 @@ class TXNumPrefixRow(PrefixRow):
|
|||
lambda: b'',
|
||||
struct.Struct(b'>32s').pack
|
||||
]
|
||||
cache_size = 1024 * 1024 * 64
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, tx_hash: bytes) -> bytes:
|
||||
|
|
@ -1167,6 +1235,8 @@ class TXHashPrefixRow(PrefixRow):
|
|||
struct.Struct(b'>L').pack
|
||||
]
|
||||
|
||||
cache_size = 1024 * 1024 * 64
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, tx_num: int) -> bytes:
|
||||
return super().pack_key(tx_num)
|
||||
|
|
@ -1196,6 +1266,7 @@ class TXPrefixRow(PrefixRow):
|
|||
lambda: b'',
|
||||
struct.Struct(b'>32s').pack
|
||||
]
|
||||
cache_size = 1024 * 1024 * 64
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, tx_hash: bytes) -> bytes:
|
||||
|
|
@ -1222,7 +1293,7 @@ class UTXOPrefixRow(PrefixRow):
|
|||
prefix = DB_PREFIXES.utxo.value
|
||||
key_struct = struct.Struct(b'>11sLH')
|
||||
value_struct = struct.Struct(b'>Q')
|
||||
|
||||
cache_size = 1024 * 1024 * 64
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>11s').pack,
|
||||
|
|
@ -1255,7 +1326,7 @@ class HashXUTXOPrefixRow(PrefixRow):
|
|||
prefix = DB_PREFIXES.hashx_utxo.value
|
||||
key_struct = struct.Struct(b'>4sLH')
|
||||
value_struct = struct.Struct(b'>11s')
|
||||
|
||||
cache_size = 1024 * 1024 * 64
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>4s').pack,
|
||||
|
|
@ -1420,7 +1491,7 @@ class SupportAmountPrefixRow(PrefixRow):
|
|||
|
||||
class DBStatePrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.db_state.value
|
||||
value_struct = struct.Struct(b'>32sLL32sLLBBlllL')
|
||||
value_struct = struct.Struct(b'>32sLL32sLLBBlllLL')
|
||||
key_struct = struct.Struct(b'')
|
||||
|
||||
key_part_lambdas = [
|
||||
|
|
@ -1437,12 +1508,16 @@ class DBStatePrefixRow(PrefixRow):
|
|||
|
||||
@classmethod
|
||||
def pack_value(cls, genesis: bytes, height: int, tx_count: int, tip: bytes, utxo_flush_count: int, wall_time: int,
|
||||
catching_up: bool, db_version: int, hist_flush_count: int, comp_flush_count: int,
|
||||
comp_cursor: int, es_sync_height: int) -> bytes:
|
||||
catching_up: bool, index_address_statuses: bool, db_version: int, hist_flush_count: int,
|
||||
comp_flush_count: int, comp_cursor: int, es_sync_height: int,
|
||||
last_indexed_address_statuses: int) -> bytes:
|
||||
bit_fields = 0
|
||||
bit_fields |= int(catching_up) << 0
|
||||
bit_fields |= int(index_address_statuses) << 1
|
||||
return super().pack_value(
|
||||
genesis, height, tx_count, tip, utxo_flush_count,
|
||||
wall_time, 1 if catching_up else 0, db_version, hist_flush_count,
|
||||
comp_flush_count, comp_cursor, es_sync_height
|
||||
wall_time, bit_fields, db_version, hist_flush_count,
|
||||
comp_flush_count, comp_cursor, es_sync_height, last_indexed_address_statuses
|
||||
)
|
||||
|
||||
@classmethod
|
||||
|
|
@ -1451,15 +1526,18 @@ class DBStatePrefixRow(PrefixRow):
|
|||
# TODO: delete this after making a new snapshot - 10/20/21
|
||||
# migrate in the es_sync_height if it doesnt exist
|
||||
data += data[32:36]
|
||||
if len(data) == 98:
|
||||
data += data[32:36]
|
||||
return DBState(*super().unpack_value(data))
|
||||
|
||||
@classmethod
|
||||
def pack_item(cls, genesis: bytes, height: int, tx_count: int, tip: bytes, utxo_flush_count: int, wall_time: int,
|
||||
catching_up: bool, db_version: int, hist_flush_count: int, comp_flush_count: int,
|
||||
comp_cursor: int, es_sync_height: int):
|
||||
catching_up: bool, index_address_statuses: bool, db_version: int, hist_flush_count: int,
|
||||
comp_flush_count: int, comp_cursor: int, es_sync_height: int, last_indexed_address_statuses: int):
|
||||
return cls.pack_key(), cls.pack_value(
|
||||
genesis, height, tx_count, tip, utxo_flush_count, wall_time, catching_up, db_version, hist_flush_count,
|
||||
comp_flush_count, comp_cursor, es_sync_height
|
||||
genesis, height, tx_count, tip, utxo_flush_count, wall_time, catching_up, index_address_statuses,
|
||||
db_version, hist_flush_count, comp_flush_count, comp_cursor, es_sync_height,
|
||||
last_indexed_address_statuses
|
||||
)
|
||||
|
||||
|
||||
|
|
@ -1693,11 +1771,134 @@ class HashXMempoolStatusPrefixRow(PrefixRow):
|
|||
return cls.pack_key(hashX), cls.pack_value(status)
|
||||
|
||||
|
||||
class EffectiveAmountKey(NamedTuple):
|
||||
claim_hash: bytes
|
||||
|
||||
|
||||
class EffectiveAmountValue(NamedTuple):
|
||||
activated_sum: int
|
||||
activated_support_sum: int
|
||||
|
||||
|
||||
class EffectiveAmountPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.effective_amount.value
|
||||
key_struct = struct.Struct(b'>20s')
|
||||
value_struct = struct.Struct(b'>QQ')
|
||||
cache_size = 1024 * 1024 * 64
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>20s').pack
|
||||
]
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, claim_hash: bytes):
|
||||
return super().pack_key(claim_hash)
|
||||
|
||||
@classmethod
|
||||
def unpack_key(cls, key: bytes) -> EffectiveAmountKey:
|
||||
return EffectiveAmountKey(*super().unpack_key(key))
|
||||
|
||||
@classmethod
|
||||
def pack_value(cls, effective_amount: int, support_sum: int) -> bytes:
|
||||
assert effective_amount >= support_sum
|
||||
return super().pack_value(effective_amount, support_sum)
|
||||
|
||||
@classmethod
|
||||
def unpack_value(cls, data: bytes) -> EffectiveAmountValue:
|
||||
return EffectiveAmountValue(*cls.value_struct.unpack(data))
|
||||
|
||||
@classmethod
|
||||
def pack_item(cls, claim_hash: bytes, effective_amount: int, support_sum: int):
|
||||
return cls.pack_key(claim_hash), cls.pack_value(effective_amount, support_sum)
|
||||
|
||||
|
||||
class FutureEffectiveAmountKey(NamedTuple):
|
||||
claim_hash: bytes
|
||||
|
||||
|
||||
class FutureEffectiveAmountValue(NamedTuple):
|
||||
future_effective_amount: int
|
||||
|
||||
|
||||
class FutureEffectiveAmountPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.future_effective_amount.value
|
||||
key_struct = struct.Struct(b'>20s')
|
||||
value_struct = struct.Struct(b'>Q')
|
||||
cache_size = 1024 * 1024 * 64
|
||||
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>20s').pack
|
||||
]
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, claim_hash: bytes):
|
||||
return super().pack_key(claim_hash)
|
||||
|
||||
@classmethod
|
||||
def unpack_key(cls, key: bytes) -> FutureEffectiveAmountKey:
|
||||
return FutureEffectiveAmountKey(*super().unpack_key(key))
|
||||
|
||||
@classmethod
|
||||
def pack_value(cls, future_effective_amount: int) -> bytes:
|
||||
return super().pack_value(future_effective_amount)
|
||||
|
||||
@classmethod
|
||||
def unpack_value(cls, data: bytes) -> FutureEffectiveAmountValue:
|
||||
return FutureEffectiveAmountValue(*cls.value_struct.unpack(data))
|
||||
|
||||
@classmethod
|
||||
def pack_item(cls, claim_hash: bytes, future_effective_amount: int):
|
||||
return cls.pack_key(claim_hash), cls.pack_value(future_effective_amount)
|
||||
|
||||
|
||||
class HashXHistoryHasherKey(NamedTuple):
|
||||
hashX: bytes
|
||||
|
||||
|
||||
class HashXHistoryHasherValue(NamedTuple):
|
||||
hasher: ResumableSHA256
|
||||
|
||||
|
||||
class HashXHistoryHasherPrefixRow(PrefixRow):
|
||||
prefix = DB_PREFIXES.hashX_history_hash.value
|
||||
key_struct = struct.Struct(b'>11s')
|
||||
value_struct = struct.Struct(b'>120s')
|
||||
cache_size = 1024 * 1024 * 64
|
||||
|
||||
key_part_lambdas = [
|
||||
lambda: b'',
|
||||
struct.Struct(b'>11s').pack
|
||||
]
|
||||
|
||||
@classmethod
|
||||
def pack_key(cls, hashX: bytes):
|
||||
return super().pack_key(hashX)
|
||||
|
||||
@classmethod
|
||||
def unpack_key(cls, key: bytes) -> HashXHistoryHasherKey:
|
||||
return HashXHistoryHasherKey(*super().unpack_key(key))
|
||||
|
||||
@classmethod
|
||||
def pack_value(cls, hasher: ResumableSHA256) -> bytes:
|
||||
return super().pack_value(hasher.get_state())
|
||||
|
||||
@classmethod
|
||||
def unpack_value(cls, data: bytes) -> HashXHistoryHasherValue:
|
||||
return HashXHistoryHasherValue(ResumableSHA256(*super().unpack_value(data)))
|
||||
|
||||
@classmethod
|
||||
def pack_item(cls, hashX: bytes, hasher: ResumableSHA256):
|
||||
return cls.pack_key(hashX), cls.pack_value(hasher)
|
||||
|
||||
|
||||
class PrefixDB(BasePrefixDB):
|
||||
def __init__(self, path: str, cache_mb: int = 128, reorg_limit: int = 200, max_open_files: int = 64,
|
||||
secondary_path: str = '', unsafe_prefixes: Optional[typing.Set[bytes]] = None):
|
||||
def __init__(self, path: str, reorg_limit: int = 200, max_open_files: int = 64,
|
||||
secondary_path: str = '', unsafe_prefixes: Optional[typing.Set[bytes]] = None,
|
||||
enforce_integrity: bool = True):
|
||||
super().__init__(path, max_open_files=max_open_files, secondary_path=secondary_path,
|
||||
max_undo_depth=reorg_limit, unsafe_prefixes=unsafe_prefixes)
|
||||
max_undo_depth=reorg_limit, unsafe_prefixes=unsafe_prefixes,
|
||||
enforce_integrity=enforce_integrity)
|
||||
db = self._db
|
||||
self.claim_to_support = ClaimToSupportPrefixRow(db, self._op_stack)
|
||||
self.support_to_claim = SupportToClaimPrefixRow(db, self._op_stack)
|
||||
|
|
@ -1711,9 +1912,10 @@ class PrefixDB(BasePrefixDB):
|
|||
self.pending_activation = PendingActivationPrefixRow(db, self._op_stack)
|
||||
self.activated = ActivatedPrefixRow(db, self._op_stack)
|
||||
self.active_amount = ActiveAmountPrefixRow(db, self._op_stack)
|
||||
self.effective_amount = EffectiveAmountPrefixRow(db, self._op_stack)
|
||||
self.bid_order = BidOrderPrefixRow(db, self._op_stack)
|
||||
self.repost = RepostPrefixRow(db, self._op_stack)
|
||||
self.reposted_claim = RepostedPrefixRow(db, self._op_stack)
|
||||
self.reposted_count = RepostedCountPrefixRow(db, self._op_stack)
|
||||
self.undo = UndoPrefixRow(db, self._op_stack)
|
||||
self.utxo = UTXOPrefixRow(db, self._op_stack)
|
||||
self.hashX_utxo = HashXUTXOPrefixRow(db, self._op_stack)
|
||||
|
|
@ -1734,6 +1936,9 @@ class PrefixDB(BasePrefixDB):
|
|||
self.touched_hashX = TouchedHashXPrefixRow(db, self._op_stack)
|
||||
self.hashX_status = HashXStatusPrefixRow(db, self._op_stack)
|
||||
self.hashX_mempool_status = HashXMempoolStatusPrefixRow(db, self._op_stack)
|
||||
self.effective_amount = EffectiveAmountPrefixRow(db, self._op_stack)
|
||||
self.future_effective_amount = FutureEffectiveAmountPrefixRow(db, self._op_stack)
|
||||
self.hashX_history_hasher = HashXHistoryHasherPrefixRow(db, self._op_stack)
|
||||
|
||||
|
||||
def auto_decode_item(key: bytes, value: bytes) -> Union[Tuple[NamedTuple, NamedTuple], Tuple[bytes, bytes]]:
|
||||
347
hub/db/revertable.py
Normal file
347
hub/db/revertable.py
Normal file
|
|
@ -0,0 +1,347 @@
|
|||
import struct
|
||||
import logging
|
||||
from string import printable
|
||||
from collections import defaultdict, deque
|
||||
from typing import Tuple, Iterable, Callable, Optional, List, Deque
|
||||
from hub.db.common import DB_PREFIXES
|
||||
|
||||
_OP_STRUCT = struct.Struct('>BLL')
|
||||
log = logging.getLogger(__name__)
|
||||
|
||||
|
||||
class RevertableOp:
|
||||
__slots__ = [
|
||||
'key',
|
||||
'value',
|
||||
]
|
||||
is_put = 0
|
||||
|
||||
def __init__(self, key: bytes, value: bytes):
|
||||
self.key = key
|
||||
self.value = value
|
||||
|
||||
@property
|
||||
def is_delete(self) -> bool:
|
||||
return not self.is_put
|
||||
|
||||
def invert(self) -> 'RevertableOp':
|
||||
raise NotImplementedError()
|
||||
|
||||
def pack(self) -> bytes:
|
||||
"""
|
||||
Serialize to bytes
|
||||
"""
|
||||
return struct.pack(
|
||||
f'>BLL{len(self.key)}s{len(self.value)}s', int(self.is_put), len(self.key), len(self.value), self.key,
|
||||
self.value
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def unpack(cls, packed: bytes) -> Tuple['RevertableOp', bytes]:
|
||||
"""
|
||||
Deserialize from bytes
|
||||
|
||||
:param packed: bytes containing at least one packed revertable op
|
||||
:return: tuple of the deserialized op (a put or a delete) and the remaining serialized bytes
|
||||
"""
|
||||
is_put, key_len, val_len = _OP_STRUCT.unpack(packed[:9])
|
||||
key = packed[9:9 + key_len]
|
||||
value = packed[9 + key_len:9 + key_len + val_len]
|
||||
if is_put == 1:
|
||||
return RevertablePut(key, value), packed[9 + key_len + val_len:]
|
||||
return RevertableDelete(key, value), packed[9 + key_len + val_len:]
|
||||
|
||||
def __eq__(self, other: 'RevertableOp') -> bool:
|
||||
return (self.is_put, self.key, self.value) == (other.is_put, other.key, other.value)
|
||||
|
||||
def __repr__(self) -> str:
|
||||
return str(self)
|
||||
|
||||
def __str__(self) -> str:
|
||||
from hub.db.prefixes import auto_decode_item
|
||||
k, v = auto_decode_item(self.key, self.value)
|
||||
key = ''.join(c if c in printable else '.' for c in str(k))
|
||||
val = ''.join(c if c in printable else '.' for c in str(v))
|
||||
return f"{'PUT' if self.is_put else 'DELETE'} {DB_PREFIXES(self.key[:1]).name}: {key} | {val}"
|
||||
|
||||
|
||||
class RevertableDelete(RevertableOp):
|
||||
def invert(self):
|
||||
return RevertablePut(self.key, self.value)
|
||||
|
||||
|
||||
class RevertablePut(RevertableOp):
|
||||
is_put = True
|
||||
|
||||
def invert(self):
|
||||
return RevertableDelete(self.key, self.value)
|
||||
|
||||
|
||||
class OpStackIntegrity(Exception):
|
||||
pass
|
||||
|
||||
|
||||
class RevertableOpStack:
|
||||
def __init__(self, get_fn: Callable[[bytes], Optional[bytes]],
|
||||
multi_get_fn: Callable[[List[bytes]], Iterable[Optional[bytes]]], unsafe_prefixes=None,
|
||||
enforce_integrity=True):
|
||||
"""
|
||||
This represents a sequence of revertable puts and deletes to a key-value database that checks for integrity
|
||||
violations when applying the puts and deletes. The integrity checks assure that keys that do not exist
|
||||
are not deleted, and that when keys are deleted the current value is correctly known so that the delete
|
||||
may be undone. When putting values, the integrity checks assure that existing values are not overwritten
|
||||
without first being deleted. Updates are performed by applying a delete op for the old value and a put op
|
||||
for the new value.
|
||||
|
||||
:param get_fn: getter function from an object implementing `KeyValueStorage`
|
||||
:param unsafe_prefixes: optional set of prefixes to ignore integrity errors for, violations are still logged
|
||||
"""
|
||||
self._get = get_fn
|
||||
self._multi_get = multi_get_fn
|
||||
# a defaultdict of verified ops ready to be applied
|
||||
self._items = defaultdict(list)
|
||||
# a faster deque of ops that have not yet been checked for integrity errors
|
||||
self._stash: Deque[RevertableOp] = deque()
|
||||
self._stashed_last_op_for_key = {}
|
||||
self._unsafe_prefixes = unsafe_prefixes or set()
|
||||
self._enforce_integrity = enforce_integrity
|
||||
|
||||
def stash_ops(self, ops: Iterable[RevertableOp]):
|
||||
self._stash.extend(ops)
|
||||
for op in ops:
|
||||
self._stashed_last_op_for_key[op.key] = op
|
||||
|
||||
def validate_and_apply_stashed_ops(self):
|
||||
if not self._stash:
|
||||
return
|
||||
|
||||
ops_to_apply = []
|
||||
append_op_needed = ops_to_apply.append
|
||||
pop_staged_op = self._stash.popleft
|
||||
unique_keys = set()
|
||||
|
||||
# nullify the ops that cancel against the most recent staged for a key
|
||||
while self._stash:
|
||||
op = pop_staged_op()
|
||||
if self._items[op.key] and op.invert() == self._items[op.key][-1]:
|
||||
self._items[op.key].pop() # if the new op is the inverse of the last op, we can safely null both
|
||||
continue
|
||||
elif self._items[op.key] and self._items[op.key][-1] == op: # duplicate of last op
|
||||
continue # raise an error?
|
||||
else:
|
||||
append_op_needed(op)
|
||||
unique_keys.add(op.key)
|
||||
|
||||
existing = {}
|
||||
if self._enforce_integrity and unique_keys:
|
||||
unique_keys = list(unique_keys)
|
||||
for idx in range(0, len(unique_keys), 10000):
|
||||
batch = unique_keys[idx:idx+10000]
|
||||
existing.update({
|
||||
k: v for k, v in zip(batch, self._multi_get(batch))
|
||||
})
|
||||
|
||||
for op in ops_to_apply:
|
||||
if op.key in self._items and len(self._items[op.key]) and self._items[op.key][-1] == op.invert():
|
||||
self._items[op.key].pop()
|
||||
if not self._items[op.key]:
|
||||
self._items.pop(op.key)
|
||||
continue
|
||||
if not self._enforce_integrity:
|
||||
self._items[op.key].append(op)
|
||||
continue
|
||||
stored_val = existing[op.key]
|
||||
has_stored_val = stored_val is not None
|
||||
delete_stored_op = None if not has_stored_val else RevertableDelete(op.key, stored_val)
|
||||
will_delete_existing_stored = False if delete_stored_op is None else (delete_stored_op in self._items[op.key])
|
||||
try:
|
||||
if op.is_delete:
|
||||
if has_stored_val and stored_val != op.value and not will_delete_existing_stored:
|
||||
# there is a value and we're not deleting it in this op
|
||||
# check that a delete for the stored value is in the stack
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect existing value {op}\nvs\n{stored_val}")
|
||||
elif not has_stored_val:
|
||||
raise OpStackIntegrity(f"db op tries to delete nonexistent key: {op}")
|
||||
elif stored_val != op.value:
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect value: {op}")
|
||||
else:
|
||||
if has_stored_val and not will_delete_existing_stored:
|
||||
raise OpStackIntegrity(f"db op tries to overwrite before deleting existing: {op}")
|
||||
if op.key in self._items and len(self._items[op.key]) and self._items[op.key][-1].is_put:
|
||||
raise OpStackIntegrity(f"db op tries to overwrite with {op} before deleting pending "
|
||||
f"{self._items[op.key][-1]}")
|
||||
except OpStackIntegrity as err:
|
||||
if op.key[:1] in self._unsafe_prefixes:
|
||||
log.debug(f"skipping over integrity error: {err}")
|
||||
else:
|
||||
raise err
|
||||
self._items[op.key].append(op)
|
||||
|
||||
self._stashed_last_op_for_key.clear()
|
||||
|
||||
def append_op(self, op: RevertableOp):
|
||||
"""
|
||||
Apply a put or delete op, checking that it introduces no integrity errors
|
||||
"""
|
||||
|
||||
inverted = op.invert()
|
||||
if self._items[op.key] and inverted == self._items[op.key][-1]:
|
||||
self._items[op.key].pop() # if the new op is the inverse of the last op, we can safely null both
|
||||
return
|
||||
elif self._items[op.key] and self._items[op.key][-1] == op: # duplicate of last op
|
||||
return # raise an error?
|
||||
stored_val = self._get(op.key)
|
||||
has_stored_val = stored_val is not None
|
||||
delete_stored_op = None if not has_stored_val else RevertableDelete(op.key, stored_val)
|
||||
will_delete_existing_stored = False if delete_stored_op is None else (delete_stored_op in self._items[op.key])
|
||||
try:
|
||||
if op.is_put and has_stored_val and not will_delete_existing_stored:
|
||||
raise OpStackIntegrity(
|
||||
f"db op tries to add on top of existing key without deleting first: {op}"
|
||||
)
|
||||
elif op.is_delete and has_stored_val and stored_val != op.value and not will_delete_existing_stored:
|
||||
# there is a value and we're not deleting it in this op
|
||||
# check that a delete for the stored value is in the stack
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect existing value {op}")
|
||||
elif op.is_delete and not has_stored_val:
|
||||
raise OpStackIntegrity(f"db op tries to delete nonexistent key: {op}")
|
||||
elif op.is_delete and stored_val != op.value:
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect value: {op}")
|
||||
except OpStackIntegrity as err:
|
||||
if op.key[:1] in self._unsafe_prefixes:
|
||||
log.debug(f"skipping over integrity error: {err}")
|
||||
else:
|
||||
raise err
|
||||
self._items[op.key].append(op)
|
||||
|
||||
def multi_put(self, ops: List[RevertablePut]):
|
||||
"""
|
||||
Apply a put or delete op, checking that it introduces no integrity errors
|
||||
"""
|
||||
|
||||
if not ops:
|
||||
return
|
||||
|
||||
need_put = []
|
||||
|
||||
if not all(op.is_put for op in ops):
|
||||
raise ValueError(f"list must contain only puts")
|
||||
if not len(set(map(lambda op: op.key, ops))) == len(ops):
|
||||
raise ValueError(f"list must contain unique keys")
|
||||
|
||||
for op in ops:
|
||||
if self._items[op.key] and op.invert() == self._items[op.key][-1]:
|
||||
self._items[op.key].pop() # if the new op is the inverse of the last op, we can safely null both
|
||||
continue
|
||||
elif self._items[op.key] and self._items[op.key][-1] == op: # duplicate of last op
|
||||
continue # raise an error?
|
||||
else:
|
||||
need_put.append(op)
|
||||
|
||||
for op, stored_val in zip(need_put, self._multi_get(list(map(lambda item: item.key, need_put)))):
|
||||
has_stored_val = stored_val is not None
|
||||
delete_stored_op = None if not has_stored_val else RevertableDelete(op.key, stored_val)
|
||||
will_delete_existing_stored = False if delete_stored_op is None else (delete_stored_op in self._items[op.key])
|
||||
try:
|
||||
if has_stored_val and not will_delete_existing_stored:
|
||||
raise OpStackIntegrity(f"db op tries to overwrite before deleting existing: {op}")
|
||||
except OpStackIntegrity as err:
|
||||
if op.key[:1] in self._unsafe_prefixes:
|
||||
log.debug(f"skipping over integrity error: {err}")
|
||||
else:
|
||||
raise err
|
||||
self._items[op.key].append(op)
|
||||
|
||||
def multi_delete(self, ops: List[RevertableDelete]):
|
||||
"""
|
||||
Apply a put or delete op, checking that it introduces no integrity errors
|
||||
"""
|
||||
|
||||
if not ops:
|
||||
return
|
||||
|
||||
need_delete = []
|
||||
|
||||
if not all(op.is_delete for op in ops):
|
||||
raise ValueError(f"list must contain only deletes")
|
||||
if not len(set(map(lambda op: op.key, ops))) == len(ops):
|
||||
raise ValueError(f"list must contain unique keys")
|
||||
|
||||
for op in ops:
|
||||
if self._items[op.key] and op.invert() == self._items[op.key][-1]:
|
||||
self._items[op.key].pop() # if the new op is the inverse of the last op, we can safely null both
|
||||
continue
|
||||
elif self._items[op.key] and self._items[op.key][-1] == op: # duplicate of last op
|
||||
continue # raise an error?
|
||||
else:
|
||||
need_delete.append(op)
|
||||
|
||||
for op, stored_val in zip(need_delete, self._multi_get(list(map(lambda item: item.key, need_delete)))):
|
||||
has_stored_val = stored_val is not None
|
||||
delete_stored_op = None if not has_stored_val else RevertableDelete(op.key, stored_val)
|
||||
will_delete_existing_stored = False if delete_stored_op is None else (delete_stored_op in self._items[op.key])
|
||||
try:
|
||||
if op.is_delete and has_stored_val and stored_val != op.value and not will_delete_existing_stored:
|
||||
# there is a value and we're not deleting it in this op
|
||||
# check that a delete for the stored value is in the stack
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect existing value {op}")
|
||||
elif not stored_val:
|
||||
raise OpStackIntegrity(f"db op tries to delete nonexistent key: {op}")
|
||||
elif op.is_delete and stored_val != op.value:
|
||||
raise OpStackIntegrity(f"db op tries to delete with incorrect value: {op}")
|
||||
except OpStackIntegrity as err:
|
||||
if op.key[:1] in self._unsafe_prefixes:
|
||||
log.debug(f"skipping over integrity error: {err}")
|
||||
else:
|
||||
raise err
|
||||
self._items[op.key].append(op)
|
||||
|
||||
def clear(self):
|
||||
self._items.clear()
|
||||
self._stash.clear()
|
||||
self._stashed_last_op_for_key.clear()
|
||||
|
||||
def __len__(self):
|
||||
return sum(map(len, self._items.values()))
|
||||
|
||||
def __iter__(self):
|
||||
for key, ops in self._items.items():
|
||||
for op in ops:
|
||||
yield op
|
||||
|
||||
def __reversed__(self):
|
||||
for key, ops in self._items.items():
|
||||
for op in reversed(ops):
|
||||
yield op
|
||||
|
||||
def get_undo_ops(self) -> bytes:
|
||||
"""
|
||||
Get the serialized bytes to undo all of the changes made by the pending ops
|
||||
"""
|
||||
return b''.join(op.invert().pack() for op in reversed(self))
|
||||
|
||||
def apply_packed_undo_ops(self, packed: bytes):
|
||||
"""
|
||||
Unpack and apply a sequence of undo ops from serialized undo bytes
|
||||
"""
|
||||
offset = 0
|
||||
packed_size = len(packed)
|
||||
while offset < packed_size:
|
||||
is_put, key_len, val_len = _OP_STRUCT.unpack(packed[offset:offset + 9])
|
||||
offset += 9
|
||||
key = packed[offset:offset + key_len]
|
||||
offset += key_len
|
||||
value = packed[offset:offset + val_len]
|
||||
offset += val_len
|
||||
if is_put == 1:
|
||||
op = RevertablePut(key, value)
|
||||
else:
|
||||
op = RevertableDelete(key, value)
|
||||
self._stash.append(op)
|
||||
self._stashed_last_op_for_key[op.key] = op
|
||||
|
||||
def get_pending_op(self, key: bytes) -> Optional[RevertableOp]:
|
||||
if key in self._stashed_last_op_for_key:
|
||||
return self._stashed_last_op_for_key[key]
|
||||
if key in self._items and self._items[key]:
|
||||
return self._items[key][-1]
|
||||
|
|
@ -2,21 +2,20 @@ import os
|
|||
import logging
|
||||
import traceback
|
||||
import argparse
|
||||
from scribe.env import Env
|
||||
from scribe.common import setup_logging
|
||||
from scribe.elasticsearch.service import ElasticSyncService
|
||||
from hub.common import setup_logging
|
||||
from hub.elastic_sync.env import ElasticEnv
|
||||
from hub.elastic_sync.service import ElasticSyncService
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
prog='scribe-elastic-sync'
|
||||
)
|
||||
Env.contribute_to_arg_parser(parser)
|
||||
parser.add_argument('--reindex', type=bool, default=False)
|
||||
ElasticEnv.contribute_to_arg_parser(parser)
|
||||
args = parser.parse_args()
|
||||
|
||||
try:
|
||||
env = Env.from_arg_parser(args)
|
||||
env = ElasticEnv.from_arg_parser(args)
|
||||
setup_logging(os.path.join(env.db_dir, 'scribe-elastic-sync.log'))
|
||||
server = ElasticSyncService(env)
|
||||
server.run(args.reindex)
|
||||
230
hub/elastic_sync/db.py
Normal file
230
hub/elastic_sync/db.py
Normal file
|
|
@ -0,0 +1,230 @@
|
|||
from typing import Optional, Set, Dict, List
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from hub.schema.claim import guess_stream_type
|
||||
from hub.schema.result import Censor
|
||||
from hub.common import hash160, STREAM_TYPES, CLAIM_TYPES, LRUCache
|
||||
from hub.db import SecondaryDB
|
||||
from hub.db.common import ResolveResult
|
||||
|
||||
|
||||
class ElasticSyncDB(SecondaryDB):
|
||||
def __init__(self, coin, db_dir: str, secondary_name: str, max_open_files: int = -1, reorg_limit: int = 200,
|
||||
cache_all_tx_hashes: bool = False,
|
||||
blocking_channel_ids: List[str] = None,
|
||||
filtering_channel_ids: List[str] = None, executor: ThreadPoolExecutor = None,
|
||||
index_address_status=False):
|
||||
super().__init__(coin, db_dir, secondary_name, max_open_files, reorg_limit,
|
||||
cache_all_tx_hashes, blocking_channel_ids, filtering_channel_ids, executor,
|
||||
index_address_status)
|
||||
self.block_timestamp_cache = LRUCache(1024)
|
||||
|
||||
def estimate_timestamp(self, height: int) -> int:
|
||||
if height in self.block_timestamp_cache:
|
||||
return self.block_timestamp_cache[height]
|
||||
header = self.prefix_db.header.get(height, deserialize_value=False)
|
||||
timestamp = int(self.coin.genesisTime + (self.coin.averageBlockOffset * height)) \
|
||||
if not header else int.from_bytes(header[100:104], byteorder='little')
|
||||
self.block_timestamp_cache[height] = timestamp
|
||||
return timestamp
|
||||
|
||||
async def prepare_claim_metadata_batch(self, claims: Dict[bytes, ResolveResult], extras):
|
||||
metadatas = {}
|
||||
needed_txos = set()
|
||||
|
||||
for claim_hash, claim in claims.items():
|
||||
reposted_claim_hash = claim.reposted_claim_hash
|
||||
needed_txos.add((claim.tx_hash, claim.position))
|
||||
if reposted_claim_hash:
|
||||
if not reposted_claim_hash not in extras:
|
||||
continue
|
||||
reposted_claim = extras.get((reposted_claim_hash))
|
||||
if reposted_claim:
|
||||
needed_txos.add((reposted_claim.tx_hash, reposted_claim.position))
|
||||
metadatas.update(await self.get_claim_metadatas(list(needed_txos)))
|
||||
|
||||
for claim_hash, claim in claims.items():
|
||||
metadata = metadatas.get((claim.tx_hash, claim.position))
|
||||
if not metadata:
|
||||
continue
|
||||
if not metadata.is_stream or not metadata.stream.has_fee:
|
||||
fee_amount = 0
|
||||
else:
|
||||
fee_amount = int(max(metadata.stream.fee.amount or 0, 0) * 1000)
|
||||
if fee_amount >= 9223372036854775807:
|
||||
continue
|
||||
reposted_claim_hash = claim.reposted_claim_hash
|
||||
reposted_metadata = None
|
||||
if reposted_claim_hash:
|
||||
if reposted_claim_hash in extras:
|
||||
reposted_claim = extras[reposted_claim_hash]
|
||||
reposted_metadata = metadatas.get((reposted_claim.tx_hash, reposted_claim.position))
|
||||
|
||||
reposted_tags = []
|
||||
reposted_languages = []
|
||||
reposted_has_source = False
|
||||
reposted_claim_type = None
|
||||
reposted_stream_type = None
|
||||
reposted_media_type = None
|
||||
reposted_fee_amount = None
|
||||
reposted_fee_currency = None
|
||||
reposted_duration = None
|
||||
|
||||
if reposted_metadata:
|
||||
if reposted_metadata.is_stream:
|
||||
meta = reposted_metadata.stream
|
||||
elif reposted_metadata.is_channel:
|
||||
meta = reposted_metadata.channel
|
||||
elif reposted_metadata.is_collection:
|
||||
meta = reposted_metadata.collection
|
||||
elif reposted_metadata.is_repost:
|
||||
meta = reposted_metadata.repost
|
||||
else:
|
||||
continue
|
||||
reposted_tags = [tag for tag in meta.tags]
|
||||
reposted_languages = [lang.language or 'none' for lang in meta.languages] or ['none']
|
||||
reposted_has_source = False if not reposted_metadata.is_stream else reposted_metadata.stream.has_source
|
||||
reposted_claim_type = CLAIM_TYPES[reposted_metadata.claim_type]
|
||||
reposted_stream_type = STREAM_TYPES[guess_stream_type(reposted_metadata.stream.source.media_type)] \
|
||||
if reposted_has_source else 0
|
||||
reposted_media_type = reposted_metadata.stream.source.media_type if reposted_metadata.is_stream else 0
|
||||
if not reposted_metadata.is_stream or not reposted_metadata.stream.has_fee:
|
||||
reposted_fee_amount = 0
|
||||
else:
|
||||
reposted_fee_amount = int(max(reposted_metadata.stream.fee.amount or 0, 0) * 1000)
|
||||
if reposted_fee_amount >= 9223372036854775807:
|
||||
continue
|
||||
reposted_fee_currency = None if not reposted_metadata.is_stream else reposted_metadata.stream.fee.currency
|
||||
reposted_duration = None
|
||||
if reposted_metadata.is_stream and \
|
||||
(reposted_metadata.stream.video.duration or reposted_metadata.stream.audio.duration):
|
||||
reposted_duration = reposted_metadata.stream.video.duration or reposted_metadata.stream.audio.duration
|
||||
if metadata.is_stream:
|
||||
meta = metadata.stream
|
||||
elif metadata.is_channel:
|
||||
meta = metadata.channel
|
||||
elif metadata.is_collection:
|
||||
meta = metadata.collection
|
||||
elif metadata.is_repost:
|
||||
meta = metadata.repost
|
||||
else:
|
||||
continue
|
||||
claim_tags = [tag for tag in meta.tags]
|
||||
claim_languages = [lang.language or 'none' for lang in meta.languages] or ['none']
|
||||
tags = list(set(claim_tags).union(set(reposted_tags)))
|
||||
languages = list(set(claim_languages).union(set(reposted_languages)))
|
||||
blocking_channel = None
|
||||
blocked_hash = self.blocked_streams.get(claim_hash) or self.blocked_streams.get(
|
||||
reposted_claim_hash) or self.blocked_channels.get(claim_hash) or self.blocked_channels.get(
|
||||
reposted_claim_hash) or self.blocked_channels.get(claim.channel_hash)
|
||||
if blocked_hash:
|
||||
blocking_channel, blocked_hash = blocked_hash
|
||||
filtered_channel = None
|
||||
filtered_hash = self.filtered_streams.get(claim_hash) or self.filtered_streams.get(
|
||||
reposted_claim_hash) or self.filtered_channels.get(claim_hash) or self.filtered_channels.get(
|
||||
reposted_claim_hash) or self.filtered_channels.get(claim.channel_hash)
|
||||
if filtered_hash:
|
||||
filtered_channel, filtered_hash = filtered_hash
|
||||
value = {
|
||||
'claim_id': claim_hash.hex(),
|
||||
'claim_name': claim.name,
|
||||
'normalized_name': claim.normalized_name,
|
||||
'tx_id': claim.tx_hash[::-1].hex(),
|
||||
'tx_num': claim.tx_num,
|
||||
'tx_nout': claim.position,
|
||||
'amount': claim.amount,
|
||||
'timestamp': self.estimate_timestamp(claim.height),
|
||||
'creation_timestamp': self.estimate_timestamp(claim.creation_height),
|
||||
'height': claim.height,
|
||||
'creation_height': claim.creation_height,
|
||||
'activation_height': claim.activation_height,
|
||||
'expiration_height': claim.expiration_height,
|
||||
'effective_amount': claim.effective_amount,
|
||||
'support_amount': claim.support_amount,
|
||||
'is_controlling': bool(claim.is_controlling),
|
||||
'last_take_over_height': claim.last_takeover_height,
|
||||
'short_url': claim.short_url,
|
||||
'canonical_url': claim.canonical_url,
|
||||
'title': None if not metadata.is_stream else metadata.stream.title,
|
||||
'author': None if not metadata.is_stream else metadata.stream.author,
|
||||
'description': None if not metadata.is_stream else metadata.stream.description,
|
||||
'claim_type': CLAIM_TYPES[metadata.claim_type],
|
||||
'has_source': reposted_has_source if metadata.is_repost else (
|
||||
False if not metadata.is_stream else metadata.stream.has_source),
|
||||
'sd_hash': metadata.stream.source.sd_hash if metadata.is_stream and metadata.stream.has_source else None,
|
||||
'stream_type': STREAM_TYPES[guess_stream_type(metadata.stream.source.media_type)]
|
||||
if metadata.is_stream and metadata.stream.has_source
|
||||
else reposted_stream_type if metadata.is_repost else 0,
|
||||
'media_type': metadata.stream.source.media_type
|
||||
if metadata.is_stream else reposted_media_type if metadata.is_repost else None,
|
||||
'fee_amount': fee_amount if not metadata.is_repost else reposted_fee_amount,
|
||||
'fee_currency': metadata.stream.fee.currency
|
||||
if metadata.is_stream else reposted_fee_currency if metadata.is_repost else None,
|
||||
'repost_count': self.get_reposted_count(claim_hash),
|
||||
'reposted_claim_id': None if not reposted_claim_hash else reposted_claim_hash.hex(),
|
||||
'reposted_claim_type': reposted_claim_type,
|
||||
'reposted_has_source': reposted_has_source,
|
||||
'channel_id': None if not metadata.is_signed else metadata.signing_channel_hash[::-1].hex(),
|
||||
'public_key_id': None if not metadata.is_channel else
|
||||
self.coin.P2PKH_address_from_hash160(hash160(metadata.channel.public_key_bytes)),
|
||||
'signature': (metadata.signature or b'').hex() or None,
|
||||
# 'signature_digest': metadata.signature,
|
||||
'is_signature_valid': bool(claim.signature_valid),
|
||||
'tags': tags,
|
||||
'languages': languages,
|
||||
'censor_type': Censor.RESOLVE if blocked_hash else Censor.SEARCH if filtered_hash else Censor.NOT_CENSORED,
|
||||
'censoring_channel_id': (blocking_channel or filtered_channel or b'').hex() or None,
|
||||
'censoring_claim_id': (blocked_hash or filtered_hash or b'').hex() or None,
|
||||
'claims_in_channel': None if not metadata.is_channel else self.get_claims_in_channel_count(claim_hash),
|
||||
'reposted_tx_id': None if not claim.reposted_tx_hash else claim.reposted_tx_hash[::-1].hex(),
|
||||
'reposted_tx_position': claim.reposted_tx_position,
|
||||
'reposted_height': claim.reposted_height,
|
||||
'channel_tx_id': None if not claim.channel_tx_hash else claim.channel_tx_hash[::-1].hex(),
|
||||
'channel_tx_position': claim.channel_tx_position,
|
||||
'channel_height': claim.channel_height,
|
||||
}
|
||||
|
||||
if metadata.is_repost and reposted_duration is not None:
|
||||
value['duration'] = reposted_duration
|
||||
elif metadata.is_stream and (metadata.stream.video.duration or metadata.stream.audio.duration):
|
||||
value['duration'] = metadata.stream.video.duration or metadata.stream.audio.duration
|
||||
if metadata.is_stream:
|
||||
value['release_time'] = metadata.stream.release_time or value['creation_timestamp']
|
||||
elif metadata.is_repost or metadata.is_collection:
|
||||
value['release_time'] = value['creation_timestamp']
|
||||
yield value
|
||||
|
||||
async def all_claims_producer(self, batch_size: int):
|
||||
batch = []
|
||||
for k in self.prefix_db.claim_to_txo.iterate(include_value=False):
|
||||
batch.append(k.claim_hash)
|
||||
if len(batch) == batch_size:
|
||||
claims = {}
|
||||
total_extras = {}
|
||||
async for claim_hash, claim, extras in self._prepare_resolve_results(batch, include_extra=False,
|
||||
apply_blocking=False,
|
||||
apply_filtering=False):
|
||||
if not claim:
|
||||
self.logger.warning("wat")
|
||||
continue
|
||||
claims[claim_hash] = claim
|
||||
total_extras[claim_hash] = claim
|
||||
total_extras.update(extras)
|
||||
async for claim in self.prepare_claim_metadata_batch(claims, total_extras):
|
||||
if claim:
|
||||
yield claim
|
||||
batch.clear()
|
||||
if batch:
|
||||
claims = {}
|
||||
total_extras = {}
|
||||
async for claim_hash, claim, extras in self._prepare_resolve_results(batch, include_extra=False,
|
||||
apply_blocking=False,
|
||||
apply_filtering=False):
|
||||
if not claim:
|
||||
self.logger.warning("wat")
|
||||
continue
|
||||
claims[claim_hash] = claim
|
||||
total_extras[claim_hash] = claim
|
||||
total_extras.update(extras)
|
||||
async for claim in self.prepare_claim_metadata_batch(claims, total_extras):
|
||||
if claim:
|
||||
yield claim
|
||||
49
hub/elastic_sync/env.py
Normal file
49
hub/elastic_sync/env.py
Normal file
|
|
@ -0,0 +1,49 @@
|
|||
from hub.env import Env
|
||||
|
||||
|
||||
class ElasticEnv(Env):
|
||||
def __init__(self, db_dir=None, max_query_workers=None, chain=None, reorg_limit=None, prometheus_port=None,
|
||||
cache_all_tx_hashes=None, elastic_host=None, elastic_port=None,
|
||||
es_index_prefix=None, elastic_notifier_host=None, elastic_notifier_port=None,
|
||||
blocking_channel_ids=None, filtering_channel_ids=None, reindex=False):
|
||||
super().__init__(db_dir, max_query_workers, chain, reorg_limit, prometheus_port, cache_all_tx_hashes,
|
||||
blocking_channel_ids, filtering_channel_ids)
|
||||
self.elastic_host = elastic_host if elastic_host is not None else self.default('ELASTIC_HOST', 'localhost')
|
||||
self.elastic_port = elastic_port if elastic_port is not None else self.integer('ELASTIC_PORT', 9200)
|
||||
self.elastic_notifier_host = elastic_notifier_host if elastic_notifier_host is not None else self.default(
|
||||
'ELASTIC_NOTIFIER_HOST', 'localhost')
|
||||
self.elastic_notifier_port = elastic_notifier_port if elastic_notifier_port is not None else self.integer(
|
||||
'ELASTIC_NOTIFIER_PORT', 19080)
|
||||
self.es_index_prefix = es_index_prefix if es_index_prefix is not None else self.default('ES_INDEX_PREFIX', '')
|
||||
# Filtering / Blocking
|
||||
self.reindex = reindex if reindex is not None else self.boolean('REINDEX_ES', False)
|
||||
|
||||
@classmethod
|
||||
def contribute_to_arg_parser(cls, parser):
|
||||
super().contribute_to_arg_parser(parser)
|
||||
parser.add_argument('--reindex', default=False, help="Drop and rebuild the elasticsearch index.",
|
||||
action='store_true')
|
||||
parser.add_argument('--elastic_host', default=cls.default('ELASTIC_HOST', 'localhost'), type=str,
|
||||
help="Hostname or ip address of the elasticsearch instance to connect to. "
|
||||
"Can be set in env with 'ELASTIC_HOST'")
|
||||
parser.add_argument('--elastic_port', default=cls.integer('ELASTIC_PORT', 9200), type=int,
|
||||
help="Elasticsearch port to connect to. Can be set in env with 'ELASTIC_PORT'")
|
||||
parser.add_argument('--elastic_notifier_host', default=cls.default('ELASTIC_NOTIFIER_HOST', 'localhost'),
|
||||
type=str, help='elasticsearch sync notifier host, defaults to localhost')
|
||||
parser.add_argument('--elastic_notifier_port', default=cls.integer('ELASTIC_NOTIFIER_PORT', 19080), type=int,
|
||||
help='elasticsearch sync notifier port')
|
||||
parser.add_argument('--es_index_prefix', default=cls.default('ES_INDEX_PREFIX', ''), type=str)
|
||||
parser.add_argument('--query_timeout_ms', type=int, default=cls.integer('QUERY_TIMEOUT_MS', 10000),
|
||||
help="Elasticsearch query timeout, in ms. Can be set in env with 'QUERY_TIMEOUT_MS'")
|
||||
|
||||
@classmethod
|
||||
def from_arg_parser(cls, args):
|
||||
return cls(
|
||||
db_dir=args.db_dir, elastic_host=args.elastic_host,
|
||||
elastic_port=args.elastic_port, max_query_workers=args.max_query_workers, chain=args.chain,
|
||||
es_index_prefix=args.es_index_prefix, reorg_limit=args.reorg_limit,
|
||||
prometheus_port=args.prometheus_port, cache_all_tx_hashes=args.cache_all_tx_hashes,
|
||||
blocking_channel_ids=args.blocking_channel_ids,
|
||||
filtering_channel_ids=args.filtering_channel_ids, elastic_notifier_host=args.elastic_notifier_host,
|
||||
elastic_notifier_port=args.elastic_notifier_port
|
||||
)
|
||||
|
|
@ -1,3 +1,4 @@
|
|||
import errno
|
||||
import os
|
||||
import json
|
||||
import typing
|
||||
|
|
@ -5,21 +6,24 @@ import asyncio
|
|||
from collections import defaultdict
|
||||
from elasticsearch import AsyncElasticsearch, NotFoundError
|
||||
from elasticsearch.helpers import async_streaming_bulk
|
||||
from scribe.schema.result import Censor
|
||||
from scribe.service import BlockchainReaderService
|
||||
from scribe.db.revertable import RevertableOp
|
||||
from scribe.db.common import TrendingNotification, DB_PREFIXES
|
||||
from scribe.elasticsearch.notifier_protocol import ElasticNotifierProtocol
|
||||
from scribe.elasticsearch.search import IndexVersionMismatch, expand_query
|
||||
from scribe.elasticsearch.constants import ALL_FIELDS, INDEX_DEFAULT_SETTINGS
|
||||
from scribe.elasticsearch.fast_ar_trending import FAST_AR_TRENDING_SCRIPT
|
||||
from hub.schema.result import Censor
|
||||
from hub.service import BlockchainReaderService
|
||||
from hub.common import IndexVersionMismatch, ALL_FIELDS, INDEX_DEFAULT_SETTINGS, expand_query
|
||||
from hub.db.revertable import RevertableOp
|
||||
from hub.db.common import TrendingNotification, DB_PREFIXES, ResolveResult
|
||||
from hub.notifier_protocol import ElasticNotifierProtocol
|
||||
from hub.elastic_sync.fast_ar_trending import FAST_AR_TRENDING_SCRIPT
|
||||
from hub.elastic_sync.db import ElasticSyncDB
|
||||
if typing.TYPE_CHECKING:
|
||||
from hub.elastic_sync.env import ElasticEnv
|
||||
|
||||
|
||||
class ElasticSyncService(BlockchainReaderService):
|
||||
VERSION = 1
|
||||
|
||||
def __init__(self, env):
|
||||
def __init__(self, env: 'ElasticEnv'):
|
||||
super().__init__(env, 'lbry-elastic-writer', thread_workers=1, thread_prefix='lbry-elastic-writer')
|
||||
self.env = env
|
||||
# self._refresh_interval = 0.1
|
||||
self._task = None
|
||||
self.index = self.env.es_index_prefix + 'claims'
|
||||
|
|
@ -42,10 +46,34 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
self._listeners: typing.List[ElasticNotifierProtocol] = []
|
||||
self._force_reindex = False
|
||||
|
||||
async def run_es_notifier(self, synchronized: asyncio.Event):
|
||||
server = await asyncio.get_event_loop().create_server(
|
||||
lambda: ElasticNotifierProtocol(self._listeners), self.env.elastic_notifier_host, self.env.elastic_notifier_port
|
||||
def open_db(self):
|
||||
env = self.env
|
||||
self.db = ElasticSyncDB(
|
||||
env.coin, env.db_dir, self.secondary_name, -1, env.reorg_limit,
|
||||
env.cache_all_tx_hashes, blocking_channel_ids=env.blocking_channel_ids,
|
||||
filtering_channel_ids=env.filtering_channel_ids, executor=self._executor,
|
||||
index_address_status=env.index_address_status
|
||||
)
|
||||
|
||||
async def run_es_notifier(self, synchronized: asyncio.Event):
|
||||
started = False
|
||||
while not started:
|
||||
try:
|
||||
server = await asyncio.get_event_loop().create_server(
|
||||
lambda: ElasticNotifierProtocol(self._listeners),
|
||||
self.env.elastic_notifier_host,
|
||||
self.env.elastic_notifier_port
|
||||
)
|
||||
started = True
|
||||
except Exception as e:
|
||||
if not isinstance(e, asyncio.CancelledError):
|
||||
self.log.error(f'ES notifier server failed to listen on '
|
||||
f'{self.env.elastic_notifier_host}:'
|
||||
f'{self.env.elastic_notifier_port:d} : {e!r}')
|
||||
if isinstance(e, OSError) and e.errno is errno.EADDRINUSE:
|
||||
await asyncio.sleep(3)
|
||||
continue
|
||||
raise
|
||||
self.log.info("ES notifier server listening on TCP %s:%i", self.env.elastic_notifier_host,
|
||||
self.env.elastic_notifier_port)
|
||||
synchronized.set()
|
||||
|
|
@ -61,7 +89,10 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
info = {}
|
||||
if os.path.exists(self._es_info_path):
|
||||
with open(self._es_info_path, 'r') as f:
|
||||
info.update(json.loads(f.read()))
|
||||
try:
|
||||
info.update(json.loads(f.read()))
|
||||
except json.decoder.JSONDecodeError:
|
||||
self.log.warning('failed to parse es sync status file')
|
||||
self._last_wrote_height = int(info.get('height', 0))
|
||||
self._last_wrote_block_hash = info.get('block_hash', None)
|
||||
|
||||
|
|
@ -142,28 +173,32 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
return update
|
||||
|
||||
async def apply_filters(self, blocked_streams, blocked_channels, filtered_streams, filtered_channels):
|
||||
only_channels = lambda x: {k: chan for k, (chan, repost) in x.items()}
|
||||
|
||||
async def batched_update_filter(items: typing.Dict[bytes, bytes], channel: bool, censor_type: int):
|
||||
batches = [{}]
|
||||
for k, v in items.items():
|
||||
if len(batches[-1]) == 2000:
|
||||
batches.append({})
|
||||
batches[-1][k] = v
|
||||
for batch in batches:
|
||||
if batch:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(censor_type, only_channels(batch)), slices=4)
|
||||
if channel:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(censor_type, only_channels(batch), True),
|
||||
slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
|
||||
if filtered_streams:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.SEARCH, filtered_streams), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await batched_update_filter(filtered_streams, False, Censor.SEARCH)
|
||||
if filtered_channels:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.SEARCH, filtered_channels), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.SEARCH, filtered_channels, True), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await batched_update_filter(filtered_channels, True, Censor.SEARCH)
|
||||
if blocked_streams:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.RESOLVE, blocked_streams), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await batched_update_filter(blocked_streams, False, Censor.RESOLVE)
|
||||
if blocked_channels:
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.RESOLVE, blocked_channels), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await self.sync_client.update_by_query(
|
||||
self.index, body=self.update_filter_query(Censor.RESOLVE, blocked_channels, True), slices=4)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
await batched_update_filter(blocked_channels, True, Censor.RESOLVE)
|
||||
|
||||
@staticmethod
|
||||
def _upsert_claim_query(index, claim):
|
||||
|
|
@ -207,10 +242,26 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
async def _claim_producer(self):
|
||||
for deleted in self._deleted_claims:
|
||||
yield self._delete_claim_query(self.index, deleted)
|
||||
for touched in self._touched_claims:
|
||||
claim = self.db.claim_producer(touched)
|
||||
if claim:
|
||||
yield self._upsert_claim_query(self.index, claim)
|
||||
|
||||
touched_claims = list(self._touched_claims)
|
||||
|
||||
for idx in range(0, len(touched_claims), 1000):
|
||||
batch = touched_claims[idx:idx+1000]
|
||||
claims = {}
|
||||
total_extras = {}
|
||||
async for claim_hash, claim, extras in self.db._prepare_resolve_results(batch, include_extra=False,
|
||||
apply_blocking=False,
|
||||
apply_filtering=False):
|
||||
if not claim:
|
||||
self.log.warning("cannot sync claim %s", (claim_hash or b'').hex())
|
||||
continue
|
||||
claims[claim_hash] = claim
|
||||
total_extras[claim_hash] = claim
|
||||
total_extras.update(extras)
|
||||
async for claim in self.db.prepare_claim_metadata_batch(claims, total_extras):
|
||||
if claim:
|
||||
yield self._upsert_claim_query(self.index, claim)
|
||||
|
||||
for claim_hash, notifications in self._trending.items():
|
||||
yield self._update_trending_query(self.index, claim_hash, notifications)
|
||||
|
||||
|
|
@ -231,6 +282,7 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
self._advanced = True
|
||||
|
||||
def unwind(self):
|
||||
self.db.block_timestamp_cache.clear()
|
||||
reverted_block_hash = self.db.block_hashes[-1]
|
||||
super().unwind()
|
||||
packed = self.db.prefix_db.undo.get(len(self.db.tx_counts), reverted_block_hash)
|
||||
|
|
@ -394,22 +446,26 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
self.log.info("finished reindexing")
|
||||
|
||||
async def _sync_all_claims(self, batch_size=100000):
|
||||
def load_historic_trending():
|
||||
notifications = self._trending
|
||||
for k, v in self.db.prefix_db.trending_notification.iterate():
|
||||
notifications[k.claim_hash].append(TrendingNotification(k.height, v.previous_amount, v.new_amount))
|
||||
|
||||
async def all_claims_producer():
|
||||
current_height = self.db.db_height
|
||||
async for claim in self.db.all_claims_producer(batch_size=batch_size):
|
||||
yield self._upsert_claim_query(self.index, claim)
|
||||
claim_hash = bytes.fromhex(claim['claim_id'])
|
||||
if claim_hash in self._trending:
|
||||
yield self._update_trending_query(self.index, claim_hash, self._trending.pop(claim_hash))
|
||||
self._trending.clear()
|
||||
|
||||
self.log.info("loading about %i historic trending updates", self.db.prefix_db.trending_notification.estimate_num_keys())
|
||||
await asyncio.get_event_loop().run_in_executor(self._executor, load_historic_trending)
|
||||
self.log.info("loaded historic trending updates for %i claims", len(self._trending))
|
||||
self.log.info("applying trending")
|
||||
|
||||
for batch_height in range(0, current_height, 10000):
|
||||
notifications = defaultdict(list)
|
||||
for k, v in self.db.prefix_db.trending_notification.iterate(start=(batch_height,), stop=(batch_height+10000,)):
|
||||
notifications[k.claim_hash].append(TrendingNotification(k.height, v.previous_amount, v.new_amount))
|
||||
|
||||
async for (k,), v in self.db.prefix_db.claim_to_txo.multi_get_async_gen(
|
||||
self._executor, [(claim_hash,) for claim_hash in notifications]):
|
||||
if not v:
|
||||
notifications.pop(k)
|
||||
|
||||
for claim_hash, trending in notifications.items():
|
||||
yield self._update_trending_query(self.index, claim_hash, trending)
|
||||
self._trending.clear()
|
||||
|
||||
cnt = 0
|
||||
success = 0
|
||||
|
|
@ -424,7 +480,7 @@ class ElasticSyncService(BlockchainReaderService):
|
|||
else:
|
||||
success += 1
|
||||
if cnt % batch_size == 0:
|
||||
self.log.info(f"indexed {success} claims")
|
||||
self.log.info(f"indexed {success}/{cnt} claims")
|
||||
finished = True
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
self.log.info("indexed %i/%i claims", success, cnt)
|
||||
195
hub/env.py
Normal file
195
hub/env.py
Normal file
|
|
@ -0,0 +1,195 @@
|
|||
import os
|
||||
import re
|
||||
import resource
|
||||
import logging
|
||||
from collections import namedtuple
|
||||
from hub.scribe.network import LBCMainNet, LBCTestNet, LBCRegTest
|
||||
|
||||
|
||||
NetIdentity = namedtuple('NetIdentity', 'host tcp_port ssl_port nick_suffix')
|
||||
|
||||
|
||||
SEGMENT_REGEX = re.compile("(?!-)[A-Z_\\d-]{1,63}(?<!-)$", re.IGNORECASE)
|
||||
|
||||
|
||||
def is_valid_hostname(hostname):
|
||||
if len(hostname) > 255:
|
||||
return False
|
||||
# strip exactly one dot from the right, if present
|
||||
if hostname and hostname[-1] == ".":
|
||||
hostname = hostname[:-1]
|
||||
return all(SEGMENT_REGEX.match(x) for x in hostname.split("."))
|
||||
|
||||
|
||||
class Env:
|
||||
|
||||
# Peer discovery
|
||||
PD_OFF, PD_SELF, PD_ON = range(3)
|
||||
|
||||
class Error(Exception):
|
||||
pass
|
||||
|
||||
def __init__(self, db_dir=None, max_query_workers=None, chain=None, reorg_limit=None,
|
||||
prometheus_port=None, cache_all_tx_hashes=None,
|
||||
blocking_channel_ids=None, filtering_channel_ids=None, index_address_status=None):
|
||||
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.db_dir = db_dir if db_dir is not None else self.required('DB_DIRECTORY')
|
||||
self.obsolete(['UTXO_MB', 'HIST_MB', 'NETWORK'])
|
||||
self.max_query_workers = max_query_workers if max_query_workers is not None else self.integer('MAX_QUERY_WORKERS', 4)
|
||||
if chain == 'mainnet':
|
||||
self.coin = LBCMainNet
|
||||
elif chain == 'testnet':
|
||||
self.coin = LBCTestNet
|
||||
else:
|
||||
self.coin = LBCRegTest
|
||||
self.reorg_limit = reorg_limit if reorg_limit is not None else self.integer('REORG_LIMIT', self.coin.REORG_LIMIT)
|
||||
self.prometheus_port = prometheus_port if prometheus_port is not None else self.integer('PROMETHEUS_PORT', 0)
|
||||
self.cache_all_tx_hashes = cache_all_tx_hashes if cache_all_tx_hashes is not None else self.boolean('CACHE_ALL_TX_HASHES', False)
|
||||
# Filtering / Blocking
|
||||
self.blocking_channel_ids = blocking_channel_ids if blocking_channel_ids is not None else self.default(
|
||||
'BLOCKING_CHANNEL_IDS', '').split(' ')
|
||||
self.filtering_channel_ids = filtering_channel_ids if filtering_channel_ids is not None else self.default(
|
||||
'FILTERING_CHANNEL_IDS', '').split(' ')
|
||||
self.index_address_status = index_address_status if index_address_status is not None else \
|
||||
self.boolean('INDEX_ADDRESS_STATUS', False)
|
||||
|
||||
@classmethod
|
||||
def default(cls, envvar, default):
|
||||
return os.environ.get(envvar, default)
|
||||
|
||||
@classmethod
|
||||
def boolean(cls, envvar, default):
|
||||
default = 'Yes' if default else ''
|
||||
return bool(cls.default(envvar, default).strip())
|
||||
|
||||
@classmethod
|
||||
def required(cls, envvar):
|
||||
value = os.environ.get(envvar)
|
||||
if value is None:
|
||||
raise cls.Error(f'required envvar {envvar} not set')
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def string_amount(cls, envvar, default):
|
||||
value = os.environ.get(envvar, default)
|
||||
amount_pattern = re.compile("[0-9]{0,10}(\.[0-9]{1,8})?")
|
||||
if len(value) > 0 and not amount_pattern.fullmatch(value):
|
||||
raise cls.Error(f'{value} is not a valid amount for {envvar}')
|
||||
return value
|
||||
|
||||
@classmethod
|
||||
def integer(cls, envvar, default):
|
||||
value = os.environ.get(envvar)
|
||||
if value is None:
|
||||
return default
|
||||
try:
|
||||
return int(value)
|
||||
except Exception:
|
||||
raise cls.Error(f'cannot convert envvar {envvar} value {value} to an integer')
|
||||
|
||||
@classmethod
|
||||
def custom(cls, envvar, default, parse):
|
||||
value = os.environ.get(envvar)
|
||||
if value is None:
|
||||
return default
|
||||
try:
|
||||
return parse(value)
|
||||
except Exception as e:
|
||||
raise cls.Error(f'cannot parse envvar {envvar} value {value}') from e
|
||||
|
||||
@classmethod
|
||||
def obsolete(cls, envvars):
|
||||
bad = [envvar for envvar in envvars if os.environ.get(envvar)]
|
||||
if bad:
|
||||
raise cls.Error(f'remove obsolete os.environment variables {bad}')
|
||||
|
||||
def cs_host(self):
|
||||
"""Returns the 'host' argument to pass to asyncio's create_server
|
||||
call. The result can be a single host name string, a list of
|
||||
host name strings, or an empty string to bind to all interfaces.
|
||||
|
||||
If rpc is True the host to use for the RPC server is returned.
|
||||
Otherwise the host to use for SSL/TCP servers is returned.
|
||||
"""
|
||||
host = self.host
|
||||
result = [part.strip() for part in host.split(',')]
|
||||
if len(result) == 1:
|
||||
result = result[0]
|
||||
if result == 'localhost':
|
||||
# 'localhost' resolves to ::1 (ipv6) on many systems, which fails on default setup of
|
||||
# docker, using 127.0.0.1 instead forces ipv4
|
||||
result = '127.0.0.1'
|
||||
return result
|
||||
|
||||
def sane_max_sessions(self):
|
||||
"""Return the maximum number of sessions to permit. Normally this
|
||||
is MAX_SESSIONS. However, to prevent open file exhaustion, ajdust
|
||||
downwards if running with a small open file rlimit."""
|
||||
env_value = self.integer('MAX_SESSIONS', 1000)
|
||||
nofile_limit = resource.getrlimit(resource.RLIMIT_NOFILE)[0]
|
||||
# We give the DB 250 files; allow ElectrumX 100 for itself
|
||||
value = max(0, min(env_value, nofile_limit - 350))
|
||||
if value < env_value:
|
||||
self.logger.warning(f'lowered maximum sessions from {env_value:,d} to {value:,d} '
|
||||
f'because your open file limit is {nofile_limit:,d}')
|
||||
return value
|
||||
|
||||
def peer_discovery_enum(self):
|
||||
pd = self.default('PEER_DISCOVERY', 'on').strip().lower()
|
||||
if pd in ('off', ''):
|
||||
return self.PD_OFF
|
||||
elif pd == 'self':
|
||||
return self.PD_SELF
|
||||
else:
|
||||
return self.PD_ON
|
||||
|
||||
def extract_peer_hubs(self):
|
||||
peer_hubs = self.default('PEER_HUBS', '')
|
||||
if not peer_hubs:
|
||||
return []
|
||||
return [hub.strip() for hub in peer_hubs.split(',')]
|
||||
|
||||
@classmethod
|
||||
def contribute_to_arg_parser(cls, parser):
|
||||
"""
|
||||
Settings used by all services
|
||||
"""
|
||||
|
||||
env_db_dir = cls.default('DB_DIRECTORY', None)
|
||||
parser.add_argument('--db_dir', type=str, required=env_db_dir is None,
|
||||
help="Path of the directory containing lbry-rocksdb. ", default=env_db_dir)
|
||||
parser.add_argument('--reorg_limit', default=cls.integer('REORG_LIMIT', 200), type=int, help='Max reorg depth')
|
||||
parser.add_argument('--chain', type=str, default=cls.default('NET', 'mainnet'),
|
||||
help="Which chain to use, default is mainnet, others are used for testing",
|
||||
choices=['mainnet', 'regtest', 'testnet'])
|
||||
parser.add_argument('--max_query_workers', type=int, default=cls.integer('MAX_QUERY_WORKERS', 4),
|
||||
help="Size of the thread pool. Can be set in env with 'MAX_QUERY_WORKERS'")
|
||||
parser.add_argument('--cache_all_tx_hashes', action='store_true',
|
||||
help="Load all tx hashes into memory. This will make address subscriptions and sync, "
|
||||
"resolve, transaction fetching, and block sync all faster at the expense of higher "
|
||||
"memory usage (at least 10GB more). Can be set in env with 'CACHE_ALL_TX_HASHES'.",
|
||||
default=cls.boolean('CACHE_ALL_TX_HASHES', False))
|
||||
parser.add_argument('--prometheus_port', type=int, default=cls.integer('PROMETHEUS_PORT', 0),
|
||||
help="Port for prometheus metrics to listen on, disabled by default. "
|
||||
"Can be set in env with 'PROMETHEUS_PORT'.")
|
||||
parser.add_argument('--blocking_channel_ids', nargs='*',
|
||||
help="Space separated list of channel claim ids used for blocking. "
|
||||
"Claims that are reposted by these channels can't be resolved "
|
||||
"or returned in search results. Can be set in env with 'BLOCKING_CHANNEL_IDS'",
|
||||
default=cls.default('BLOCKING_CHANNEL_IDS', '').split(' '))
|
||||
parser.add_argument('--filtering_channel_ids', nargs='*',
|
||||
help="Space separated list of channel claim ids used for blocking. "
|
||||
"Claims that are reposted by these channels aren't returned in search results. "
|
||||
"Can be set in env with 'FILTERING_CHANNEL_IDS'",
|
||||
default=cls.default('FILTERING_CHANNEL_IDS', '').split(' '))
|
||||
parser.add_argument('--index_address_statuses', action='store_true',
|
||||
help="Use precomputed address statuses, must be enabled in the reader and the writer to "
|
||||
"use it. If disabled (the default), the status of an address must be calculated at "
|
||||
"runtime when clients request it (address subscriptions, address history sync). "
|
||||
"If enabled, scribe will maintain an index of precomputed statuses",
|
||||
default=cls.boolean('INDEX_ADDRESS_STATUS', False))
|
||||
|
||||
@classmethod
|
||||
def from_arg_parser(cls, args):
|
||||
raise NotImplementedError()
|
||||
|
|
@ -1,4 +1,7 @@
|
|||
import typing
|
||||
from .base import BaseError, claim_id
|
||||
if typing.TYPE_CHECKING:
|
||||
from hub.db.common import ResolveResult
|
||||
|
||||
|
||||
class UserInputError(BaseError):
|
||||
|
|
@ -262,11 +265,13 @@ class ResolveTimeoutError(WalletError):
|
|||
|
||||
class ResolveCensoredError(WalletError):
|
||||
|
||||
def __init__(self, url, censor_id, censor_row):
|
||||
self.url = url
|
||||
def __init__(self, censor_type: str, censored_url: str, censoring_url: str, censor_id: str, reason: str,
|
||||
censor_row: 'ResolveResult'):
|
||||
|
||||
self.url = censored_url
|
||||
self.censor_id = censor_id
|
||||
self.censor_row = censor_row
|
||||
super().__init__(f"Resolve of '{url}' was censored by channel with claim id '{censor_id}'.")
|
||||
super().__init__(f"Resolve of '{censored_url}' was {censor_type} by {censoring_url}'. Reason given: {reason}")
|
||||
|
||||
|
||||
class KeyFeeAboveMaxAllowedError(WalletError):
|
||||
|
|
@ -2,21 +2,20 @@ import os
|
|||
import logging
|
||||
import traceback
|
||||
import argparse
|
||||
from scribe.env import Env
|
||||
from scribe.common import setup_logging
|
||||
from scribe.hub.service import HubServerService
|
||||
from hub.common import setup_logging
|
||||
from hub.herald.env import ServerEnv
|
||||
from hub.herald.service import HubServerService
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
prog='scribe-hub'
|
||||
prog='herald'
|
||||
)
|
||||
Env.contribute_to_arg_parser(parser)
|
||||
ServerEnv.contribute_to_arg_parser(parser)
|
||||
args = parser.parse_args()
|
||||
|
||||
try:
|
||||
env = Env.from_arg_parser(args)
|
||||
setup_logging(os.path.join(env.db_dir, 'scribe-hub.log'))
|
||||
env = ServerEnv.from_arg_parser(args)
|
||||
setup_logging(os.path.join(env.db_dir, 'herald.log'))
|
||||
server = HubServerService(env)
|
||||
server.run()
|
||||
except Exception:
|
||||
|
|
@ -1,7 +1,7 @@
|
|||
import inspect
|
||||
from collections import namedtuple
|
||||
from functools import lru_cache
|
||||
from scribe.common import CodeMessageError
|
||||
from hub.common import CodeMessageError
|
||||
|
||||
|
||||
SignatureInfo = namedtuple('SignatureInfo', 'min_args max_args '
|
||||
33
hub/herald/db.py
Normal file
33
hub/herald/db.py
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
import asyncio
|
||||
from typing import List
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from hub.db import SecondaryDB
|
||||
|
||||
|
||||
class HeraldDB(SecondaryDB):
|
||||
def __init__(self, coin, db_dir: str, secondary_name: str, max_open_files: int = -1, reorg_limit: int = 200,
|
||||
cache_all_tx_hashes: bool = False,
|
||||
blocking_channel_ids: List[str] = None,
|
||||
filtering_channel_ids: List[str] = None, executor: ThreadPoolExecutor = None,
|
||||
index_address_status=False, merkle_cache_size=32768, tx_cache_size=32768):
|
||||
super().__init__(coin, db_dir, secondary_name, max_open_files, reorg_limit,
|
||||
cache_all_tx_hashes, blocking_channel_ids, filtering_channel_ids, executor,
|
||||
index_address_status, merkle_cache_size, tx_cache_size)
|
||||
# self.headers = None
|
||||
|
||||
# async def _read_headers(self):
|
||||
# def get_headers():
|
||||
# return [
|
||||
# header for header in self.prefix_db.header.iterate(
|
||||
# start=(0, ), stop=(self.db_height + 1, ), include_key=False, fill_cache=False,
|
||||
# deserialize_value=False
|
||||
# )
|
||||
# ]
|
||||
#
|
||||
# headers = await asyncio.get_event_loop().run_in_executor(self._executor, get_headers)
|
||||
# assert len(headers) - 1 == self.db_height, f"{len(headers)} vs {self.db_height}"
|
||||
# self.headers = headers
|
||||
|
||||
# async def initialize_caches(self):
|
||||
# await super().initialize_caches()
|
||||
# await self._read_headers()
|
||||
166
hub/herald/env.py
Normal file
166
hub/herald/env.py
Normal file
|
|
@ -0,0 +1,166 @@
|
|||
import re
|
||||
from collections import deque
|
||||
from hub.env import Env
|
||||
|
||||
ELASTIC_SERVICES_REGEX = re.compile("(([\d|\.]|[^,:\/])*:\d*\/([\d|\.]|[^,:\/])*:\d*,?)*")
|
||||
|
||||
|
||||
def parse_es_services(elastic_services_arg: str):
|
||||
match = ELASTIC_SERVICES_REGEX.match(elastic_services_arg)
|
||||
if not match:
|
||||
return []
|
||||
matching = match.group()
|
||||
services = [item.split('/') for item in matching.split(',') if item]
|
||||
return [
|
||||
((es.split(':')[0], int(es.split(':')[1])), (notifier.split(':')[0], int(notifier.split(':')[1])))
|
||||
for (es, notifier) in services
|
||||
]
|
||||
|
||||
|
||||
class ServerEnv(Env):
|
||||
def __init__(self, db_dir=None, max_query_workers=None, chain=None, reorg_limit=None,
|
||||
prometheus_port=None, cache_all_tx_hashes=None,
|
||||
daemon_url=None, host=None, elastic_services=None, es_index_prefix=None,
|
||||
tcp_port=None, udp_port=None, banner_file=None, allow_lan_udp=None, country=None,
|
||||
payment_address=None, donation_address=None, max_send=None, max_receive=None, max_sessions=None,
|
||||
session_timeout=None, drop_client=None, description=None, daily_fee=None,
|
||||
database_query_timeout=None, blocking_channel_ids=None, filtering_channel_ids=None, peer_hubs=None,
|
||||
peer_announce=None, index_address_status=None, address_history_cache_size=None, daemon_ca_path=None,
|
||||
merkle_cache_size=None, resolved_url_cache_size=None, tx_cache_size=None,
|
||||
history_tx_cache_size=None, largest_address_history_cache_size=None):
|
||||
super().__init__(db_dir, max_query_workers, chain, reorg_limit, prometheus_port, cache_all_tx_hashes,
|
||||
blocking_channel_ids, filtering_channel_ids, index_address_status)
|
||||
self.daemon_url = daemon_url if daemon_url is not None else self.required('DAEMON_URL')
|
||||
self.host = host if host is not None else self.default('HOST', 'localhost')
|
||||
self.elastic_services = deque(parse_es_services(elastic_services or 'localhost:9200/localhost:19080'))
|
||||
self.es_index_prefix = es_index_prefix if es_index_prefix is not None else self.default('ES_INDEX_PREFIX', '')
|
||||
# Server stuff
|
||||
self.tcp_port = tcp_port if tcp_port is not None else self.integer('TCP_PORT', None)
|
||||
self.udp_port = udp_port if udp_port is not None else self.integer('UDP_PORT', self.tcp_port)
|
||||
self.banner_file = banner_file if banner_file is not None else self.default('BANNER_FILE', None)
|
||||
self.allow_lan_udp = allow_lan_udp if allow_lan_udp is not None else self.boolean('ALLOW_LAN_UDP', False)
|
||||
self.country = country if country is not None else self.default('COUNTRY', 'US')
|
||||
# Peer discovery
|
||||
self.peer_discovery = self.peer_discovery_enum()
|
||||
self.peer_announce = peer_announce if peer_announce is not None else self.boolean('PEER_ANNOUNCE', True)
|
||||
if peer_hubs is not None:
|
||||
self.peer_hubs = [p.strip("") for p in peer_hubs.split(",")]
|
||||
else:
|
||||
self.peer_hubs = self.extract_peer_hubs()
|
||||
# The electrum client takes the empty string as unspecified
|
||||
self.payment_address = payment_address if payment_address is not None else self.default('PAYMENT_ADDRESS', '')
|
||||
self.donation_address = donation_address if donation_address is not None else self.default('DONATION_ADDRESS',
|
||||
'')
|
||||
# Server limits to help prevent DoS
|
||||
self.max_send = max_send if max_send is not None else self.integer('MAX_SEND', 1000000000000000000)
|
||||
self.max_receive = max_receive if max_receive is not None else self.integer('MAX_RECEIVE', 1000000000000000000)
|
||||
self.max_sessions = max_sessions if max_sessions is not None else self.sane_max_sessions()
|
||||
self.session_timeout = session_timeout if session_timeout is not None else self.integer('SESSION_TIMEOUT', 600)
|
||||
self.drop_client = re.compile(drop_client) if drop_client is not None else self.custom("DROP_CLIENT", None, re.compile)
|
||||
self.description = description if description is not None else self.default('DESCRIPTION', '')
|
||||
self.daily_fee = daily_fee if daily_fee is not None else self.string_amount('DAILY_FEE', '0')
|
||||
self.database_query_timeout = (database_query_timeout / 1000.0) if database_query_timeout is not None else \
|
||||
(float(self.integer('QUERY_TIMEOUT_MS', 10000)) / 1000.0)
|
||||
self.hashX_history_cache_size = address_history_cache_size if address_history_cache_size is not None \
|
||||
else self.integer('ADDRESS_HISTORY_CACHE_SIZE', 4096)
|
||||
self.largest_hashX_history_cache_size = largest_address_history_cache_size if largest_address_history_cache_size is not None \
|
||||
else self.integer('LARGEST_ADDRESS_HISTORY_CACHE_SIZE', 256)
|
||||
|
||||
self.daemon_ca_path = daemon_ca_path if daemon_ca_path else None
|
||||
self.merkle_cache_size = merkle_cache_size if merkle_cache_size is not None else self.integer('MERKLE_CACHE_SIZE', 32768)
|
||||
self.resolved_url_cache_size = resolved_url_cache_size if resolved_url_cache_size is not None else self.integer(
|
||||
'RESOLVED_URL_CACHE_SIZE', 32768)
|
||||
self.tx_cache_size = tx_cache_size if tx_cache_size is not None else self.integer(
|
||||
'TX_CACHE_SIZE', 32768)
|
||||
self.history_tx_cache_size = history_tx_cache_size if history_tx_cache_size is not None else \
|
||||
self.integer('HISTORY_TX_CACHE_SIZE', 4194304)
|
||||
|
||||
@classmethod
|
||||
def contribute_to_arg_parser(cls, parser):
|
||||
super().contribute_to_arg_parser(parser)
|
||||
env_daemon_url = cls.default('DAEMON_URL', None)
|
||||
parser.add_argument('--daemon_url', required=env_daemon_url is None,
|
||||
help="URL for rpc from lbrycrd or lbcd, "
|
||||
"<rpcuser>:<rpcpassword>@<lbrycrd rpc ip><lbrycrd rpc port>.",
|
||||
default=env_daemon_url)
|
||||
parser.add_argument('--daemon_ca_path', type=str, default='',
|
||||
help='Path to the lbcd ca file, used for lbcd with ssl')
|
||||
parser.add_argument('--host', type=str, default=cls.default('HOST', 'localhost'),
|
||||
help="Interface for hub server to listen on, use 0.0.0.0 to listen on the external "
|
||||
"interface. Can be set in env with 'HOST'")
|
||||
parser.add_argument('--tcp_port', type=int, default=cls.integer('TCP_PORT', 50001),
|
||||
help="Electrum TCP port to listen on for hub server. Can be set in env with 'TCP_PORT'")
|
||||
parser.add_argument('--udp_port', type=int, default=cls.integer('UDP_PORT', 50001),
|
||||
help="'UDP port to listen on for hub server. Can be set in env with 'UDP_PORT'")
|
||||
parser.add_argument('--max_sessions', type=int, default=cls.integer('MAX_SESSIONS', 100000),
|
||||
help="Maximum number of electrum clients that can be connected, defaults to 100000.")
|
||||
parser.add_argument('--max_send', type=int, default=cls.integer('MAX_SESSIONS', 1000000000000000000),
|
||||
help="Maximum size of a request")
|
||||
parser.add_argument('--max_receive', type=int, default=cls.integer('MAX_SESSIONS', 1000000000000000000),
|
||||
help="Maximum size of a response")
|
||||
parser.add_argument('--drop_client', type=str, default=cls.default('DROP_CLIENT', None),
|
||||
help="Regex used for blocking clients")
|
||||
parser.add_argument('--session_timeout', type=int, default=cls.integer('SESSION_TIMEOUT', 600),
|
||||
help="Session inactivity timeout")
|
||||
parser.add_argument('--elastic_services',
|
||||
default=cls.default('ELASTIC_SERVICES', 'localhost:9200/localhost:19080'), type=str,
|
||||
help="Hosts and ports for elastic search and the scribe elastic sync notifier. "
|
||||
"Given as a comma separated list without spaces of items in the format "
|
||||
"<elastic host>:<elastic port>/<notifier host>:<notifier port> . "
|
||||
"Defaults to 'localhost:9200/localhost:19080'. "
|
||||
"Can be set in env with 'ELASTIC_SERVICES'")
|
||||
parser.add_argument('--es_index_prefix', default=cls.default('ES_INDEX_PREFIX', ''), type=str)
|
||||
parser.add_argument('--allow_lan_udp', action='store_true',
|
||||
help="Reply to clients on the local network", default=cls.boolean('ALLOW_LAN_UDP', False))
|
||||
parser.add_argument('--description', default=cls.default('DESCRIPTION', None), type=str)
|
||||
parser.add_argument('--banner_file', default=cls.default('BANNER_FILE', None), type=str)
|
||||
parser.add_argument('--country', default=cls.default('COUNTRY', 'US'), type=str)
|
||||
parser.add_argument('--payment_address', default=cls.default('PAYMENT_ADDRESS', None), type=str)
|
||||
parser.add_argument('--donation_address', default=cls.default('DONATION_ADDRESS', None), type=str)
|
||||
parser.add_argument('--daily_fee', default=cls.default('DAILY_FEE', '0'), type=str)
|
||||
parser.add_argument('--query_timeout_ms', type=int, default=cls.integer('QUERY_TIMEOUT_MS', 10000),
|
||||
help="Elasticsearch query timeout, in ms. Can be set in env with 'QUERY_TIMEOUT_MS'")
|
||||
parser.add_argument('--largest_address_history_cache_size', type=int,
|
||||
default=cls.integer('LARGEST_ADDRESS_HISTORY_CACHE_SIZE', 256),
|
||||
help="Size of the largest value cache for address histories. "
|
||||
"Can be set in the env with 'LARGEST_ADDRESS_HISTORY_CACHE_SIZE'")
|
||||
parser.add_argument('--address_history_cache_size', type=int,
|
||||
default=cls.integer('ADDRESS_HISTORY_CACHE_SIZE', 4096),
|
||||
help="Size of the lru cache of address histories. "
|
||||
"Can be set in the env with 'ADDRESS_HISTORY_CACHE_SIZE'")
|
||||
parser.add_argument('--merkle_cache_size', type=int,
|
||||
default=cls.integer('MERKLE_CACHE_SIZE', 32768),
|
||||
help="Size of the lru cache of merkle trees for txs in blocks. "
|
||||
"Can be set in the env with 'MERKLE_CACHE_SIZE'")
|
||||
parser.add_argument('--resolved_url_cache_size', type=int,
|
||||
default=cls.integer('RESOLVED_URL_CACHE_SIZE', 32768),
|
||||
help="Size of the lru cache of resolved urls. "
|
||||
"Can be set in the env with 'RESOLVED_URL_CACHE_SIZE'")
|
||||
parser.add_argument('--tx_cache_size', type=int,
|
||||
default=cls.integer('TX_CACHE_SIZE', 32768),
|
||||
help="Size of the lru cache of transactions. "
|
||||
"Can be set in the env with 'TX_CACHE_SIZE'")
|
||||
parser.add_argument('--history_tx_cache_size', type=int,
|
||||
default=cls.integer('HISTORY_TX_CACHE_SIZE', 524288),
|
||||
help="Size of the lfu cache of txids in transaction histories for addresses. "
|
||||
"Can be set in the env with 'HISTORY_TX_CACHE_SIZE'")
|
||||
|
||||
@classmethod
|
||||
def from_arg_parser(cls, args):
|
||||
return cls(
|
||||
db_dir=args.db_dir, daemon_url=args.daemon_url, host=args.host, elastic_services=args.elastic_services,
|
||||
max_query_workers=args.max_query_workers, chain=args.chain,
|
||||
es_index_prefix=args.es_index_prefix, reorg_limit=args.reorg_limit, tcp_port=args.tcp_port,
|
||||
udp_port=args.udp_port, prometheus_port=args.prometheus_port, banner_file=args.banner_file,
|
||||
allow_lan_udp=args.allow_lan_udp, cache_all_tx_hashes=args.cache_all_tx_hashes,
|
||||
country=args.country, payment_address=args.payment_address,
|
||||
donation_address=args.donation_address, max_send=args.max_send, max_receive=args.max_receive,
|
||||
max_sessions=args.max_sessions, session_timeout=args.session_timeout,
|
||||
drop_client=args.drop_client, description=args.description, daily_fee=args.daily_fee,
|
||||
database_query_timeout=args.query_timeout_ms, blocking_channel_ids=args.blocking_channel_ids,
|
||||
filtering_channel_ids=args.filtering_channel_ids, index_address_status=args.index_address_statuses,
|
||||
address_history_cache_size=args.address_history_cache_size, daemon_ca_path=args.daemon_ca_path,
|
||||
merkle_cache_size=args.merkle_cache_size, resolved_url_cache_size=args.resolved_url_cache_size,
|
||||
tx_cache_size=args.tx_cache_size, history_tx_cache_size=args.history_tx_cache_size,
|
||||
largest_address_history_cache_size=args.largest_address_history_cache_size
|
||||
)
|
||||
|
|
@ -6,8 +6,8 @@ import asyncio
|
|||
from asyncio import Event
|
||||
from functools import partial
|
||||
from numbers import Number
|
||||
from scribe.common import RPCError, CodeMessageError
|
||||
from scribe.hub.common import Notification, Request, Response, Batch, ProtocolError
|
||||
from hub.common import RPCError, CodeMessageError
|
||||
from hub.herald.common import Notification, Request, Response, Batch, ProtocolError
|
||||
|
||||
|
||||
class JSONRPC:
|
||||
|
|
@ -6,14 +6,14 @@ import logging
|
|||
from collections import defaultdict
|
||||
from prometheus_client import Histogram, Gauge
|
||||
import rocksdb.errors
|
||||
from scribe import PROMETHEUS_NAMESPACE
|
||||
from scribe.common import HISTOGRAM_BUCKETS
|
||||
from scribe.db.common import UTXO
|
||||
from scribe.blockchain.transaction.deserializer import Deserializer
|
||||
from hub import PROMETHEUS_NAMESPACE
|
||||
from hub.common import HISTOGRAM_BUCKETS
|
||||
from hub.db.common import UTXO
|
||||
from hub.scribe.transaction.deserializer import Deserializer
|
||||
|
||||
if typing.TYPE_CHECKING:
|
||||
from scribe.hub.session import SessionManager
|
||||
from scribe.db import HubDB
|
||||
from hub.herald.session import SessionManager
|
||||
from hub.db import SecondaryDB
|
||||
|
||||
|
||||
@attr.s(slots=True)
|
||||
|
|
@ -46,7 +46,7 @@ mempool_touched_address_count_metric = Gauge(
|
|||
|
||||
|
||||
class HubMemPool:
|
||||
def __init__(self, coin, db: 'HubDB', refresh_secs=1.0):
|
||||
def __init__(self, coin, db: 'SecondaryDB', refresh_secs=1.0):
|
||||
self.coin = coin
|
||||
self._db = db
|
||||
self.logger = logging.getLogger(__name__)
|
||||
|
|
@ -157,6 +157,14 @@ class HubMemPool:
|
|||
result.append(MemPoolTxSummary(tx_hash, tx.fee, has_ui))
|
||||
return result
|
||||
|
||||
def mempool_history(self, hashX: bytes) -> str:
|
||||
result = ''
|
||||
for tx_hash in self.touched_hashXs.get(hashX, ()):
|
||||
if tx_hash not in self.txs:
|
||||
continue # the tx hash for the touched address is an input that isn't in mempool anymore
|
||||
result += f'{tx_hash[::-1].hex()}:{-any(_hash in self.txs for _hash, idx in self.txs[tx_hash].in_pairs):d}:'
|
||||
return result
|
||||
|
||||
def unordered_UTXOs(self, hashX):
|
||||
"""Return an unordered list of UTXO named tuples from mempool
|
||||
transactions that pay to hashX.
|
||||
|
|
@ -229,12 +237,13 @@ class HubMemPool:
|
|||
session = self.session_manager.sessions.get(session_id)
|
||||
if session:
|
||||
if session.subscribe_headers and height_changed:
|
||||
asyncio.create_task(
|
||||
session.send_notification('blockchain.headers.subscribe',
|
||||
(self.session_manager.hsub_results[session.subscribe_headers_raw],))
|
||||
session.send_notification(
|
||||
'blockchain.headers.subscribe',
|
||||
(self.session_manager.hsub_results[session.subscribe_headers_raw],)
|
||||
)
|
||||
|
||||
if hashXes:
|
||||
asyncio.create_task(session.send_history_notifications(*hashXes))
|
||||
session.send_history_notifications(hashXes)
|
||||
|
||||
async def _notify_sessions(self, height, touched, new_touched):
|
||||
"""Notify sessions about height changes and touched addresses."""
|
||||
|
|
@ -276,7 +285,6 @@ class HubMemPool:
|
|||
if session.subscribe_headers and height_changed:
|
||||
sent_headers += 1
|
||||
self._notification_q.put_nowait((session_id, height_changed, hashXes))
|
||||
|
||||
if sent_headers:
|
||||
self.logger.info(f'notified {sent_headers} sessions of new block header')
|
||||
if session_hashxes_to_notify:
|
||||
|
|
@ -1,23 +1,17 @@
|
|||
import logging
|
||||
import asyncio
|
||||
import struct
|
||||
from bisect import bisect_right
|
||||
from collections import Counter, deque
|
||||
from decimal import Decimal
|
||||
from operator import itemgetter
|
||||
from typing import Optional, List, Iterable, TYPE_CHECKING
|
||||
from typing import Optional, List, TYPE_CHECKING, Deque, Tuple
|
||||
|
||||
from elasticsearch import AsyncElasticsearch, NotFoundError, ConnectionError
|
||||
from scribe.schema.result import Censor, Outputs
|
||||
from scribe.schema.tags import clean_tags
|
||||
from scribe.schema.url import normalize_name
|
||||
from scribe.error import TooManyClaimSearchParametersError
|
||||
from scribe.common import LRUCache
|
||||
from scribe.db.common import CLAIM_TYPES, STREAM_TYPES
|
||||
from scribe.elasticsearch.constants import INDEX_DEFAULT_SETTINGS, REPLACEMENTS, FIELDS, TEXT_FIELDS, RANGE_FIELDS
|
||||
from scribe.db.common import ResolveResult
|
||||
from hub.schema.result import Censor, Outputs
|
||||
from hub.common import LRUCache, IndexVersionMismatch, INDEX_DEFAULT_SETTINGS, expand_query, expand_result
|
||||
from hub.db.common import ResolveResult
|
||||
if TYPE_CHECKING:
|
||||
from scribe.db import HubDB
|
||||
from prometheus_client import Counter as PrometheusCounter
|
||||
from hub.db import SecondaryDB
|
||||
|
||||
|
||||
class ChannelResolution(str):
|
||||
|
|
@ -32,19 +26,15 @@ class StreamResolution(str):
|
|||
return LookupError(f'Could not find claim at "{url}".')
|
||||
|
||||
|
||||
class IndexVersionMismatch(Exception):
|
||||
def __init__(self, got_version, expected_version):
|
||||
self.got_version = got_version
|
||||
self.expected_version = expected_version
|
||||
|
||||
|
||||
class SearchIndex:
|
||||
VERSION = 1
|
||||
|
||||
def __init__(self, hub_db: 'HubDB', index_prefix: str, search_timeout=3.0, elastic_host='localhost',
|
||||
elastic_port=9200):
|
||||
def __init__(self, hub_db: 'SecondaryDB', index_prefix: str, search_timeout=3.0,
|
||||
elastic_services: Optional[Deque[Tuple[Tuple[str, int], Tuple[str, int]]]] = None,
|
||||
timeout_counter: Optional['PrometheusCounter'] = None):
|
||||
self.hub_db = hub_db
|
||||
self.search_timeout = search_timeout
|
||||
self.timeout_counter: Optional['PrometheusCounter'] = timeout_counter
|
||||
self.sync_timeout = 600 # wont hit that 99% of the time, but can hit on a fresh import
|
||||
self.search_client: Optional[AsyncElasticsearch] = None
|
||||
self.sync_client: Optional[AsyncElasticsearch] = None
|
||||
|
|
@ -52,8 +42,8 @@ class SearchIndex:
|
|||
self.logger = logging.getLogger(__name__)
|
||||
self.claim_cache = LRUCache(2 ** 15)
|
||||
self.search_cache = LRUCache(2 ** 17)
|
||||
self._elastic_host = elastic_host
|
||||
self._elastic_port = elastic_port
|
||||
self._elastic_services = elastic_services
|
||||
self.lost_connection = asyncio.Event()
|
||||
|
||||
async def get_index_version(self) -> int:
|
||||
try:
|
||||
|
|
@ -70,9 +60,9 @@ class SearchIndex:
|
|||
async def start(self) -> bool:
|
||||
if self.sync_client:
|
||||
return False
|
||||
hosts = [{'host': self._elastic_host, 'port': self._elastic_port}]
|
||||
hosts = [{'host': self._elastic_services[0][0][0], 'port': self._elastic_services[0][0][1]}]
|
||||
self.sync_client = AsyncElasticsearch(hosts, timeout=self.sync_timeout)
|
||||
self.search_client = AsyncElasticsearch(hosts, timeout=self.search_timeout)
|
||||
self.search_client = AsyncElasticsearch(hosts, timeout=self.search_timeout+1)
|
||||
while True:
|
||||
try:
|
||||
await self.sync_client.cluster.health(wait_for_status='yellow')
|
||||
|
|
@ -91,7 +81,7 @@ class SearchIndex:
|
|||
self.logger.error("es search index has an incompatible version: %s vs %s", index_version, self.VERSION)
|
||||
raise IndexVersionMismatch(index_version, self.VERSION)
|
||||
await self.sync_client.indices.refresh(self.index)
|
||||
return acked
|
||||
return True
|
||||
|
||||
async def stop(self):
|
||||
clients = [c for c in (self.sync_client, self.search_client) if c is not None]
|
||||
|
|
@ -218,10 +208,14 @@ class SearchIndex:
|
|||
reordered_hits = cache_item.result
|
||||
else:
|
||||
query = expand_query(**kwargs)
|
||||
search_hits = deque((await self.search_client.search(
|
||||
es_resp = await self.search_client.search(
|
||||
query, index=self.index, track_total_hits=False,
|
||||
timeout=f'{int(1000*self.search_timeout)}ms',
|
||||
_source_includes=['_id', 'channel_id', 'reposted_claim_id', 'creation_height']
|
||||
))['hits']['hits'])
|
||||
)
|
||||
search_hits = deque(es_resp['hits']['hits'])
|
||||
if self.timeout_counter and es_resp['timed_out']:
|
||||
self.timeout_counter.inc()
|
||||
if remove_duplicates:
|
||||
search_hits = self.__remove_duplicates(search_hits)
|
||||
if per_channel_per_page > 0:
|
||||
|
|
@ -248,7 +242,7 @@ class SearchIndex:
|
|||
dropped.add(hit['_id'])
|
||||
return deque(hit for hit in search_hits if hit['_id'] not in dropped)
|
||||
|
||||
def __search_ahead(self, search_hits: list, page_size: int, per_channel_per_page: int):
|
||||
def __search_ahead(self, search_hits: deque, page_size: int, per_channel_per_page: int) -> list:
|
||||
reordered_hits = []
|
||||
channel_counters = Counter()
|
||||
next_page_hits_maybe_check_later = deque()
|
||||
|
|
@ -297,234 +291,6 @@ class SearchIndex:
|
|||
return referenced_txos
|
||||
|
||||
|
||||
def expand_query(**kwargs):
|
||||
if "amount_order" in kwargs:
|
||||
kwargs["limit"] = 1
|
||||
kwargs["order_by"] = "effective_amount"
|
||||
kwargs["offset"] = int(kwargs["amount_order"]) - 1
|
||||
if 'name' in kwargs:
|
||||
kwargs['name'] = normalize_name(kwargs.pop('name'))
|
||||
if kwargs.get('is_controlling') is False:
|
||||
kwargs.pop('is_controlling')
|
||||
query = {'must': [], 'must_not': []}
|
||||
collapse = None
|
||||
if 'fee_currency' in kwargs and kwargs['fee_currency'] is not None:
|
||||
kwargs['fee_currency'] = kwargs['fee_currency'].upper()
|
||||
for key, value in kwargs.items():
|
||||
key = key.replace('claim.', '')
|
||||
many = key.endswith('__in') or isinstance(value, list)
|
||||
if many and len(value) > 2048:
|
||||
raise TooManyClaimSearchParametersError(key, 2048)
|
||||
if many:
|
||||
key = key.replace('__in', '')
|
||||
value = list(filter(None, value))
|
||||
if value is None or isinstance(value, list) and len(value) == 0:
|
||||
continue
|
||||
key = REPLACEMENTS.get(key, key)
|
||||
if key in FIELDS:
|
||||
partial_id = False
|
||||
if key == 'claim_type':
|
||||
if isinstance(value, str):
|
||||
value = CLAIM_TYPES[value]
|
||||
else:
|
||||
value = [CLAIM_TYPES[claim_type] for claim_type in value]
|
||||
elif key == 'stream_type':
|
||||
value = [STREAM_TYPES[value]] if isinstance(value, str) else list(map(STREAM_TYPES.get, value))
|
||||
if key == '_id':
|
||||
if isinstance(value, Iterable):
|
||||
value = [item[::-1].hex() for item in value]
|
||||
else:
|
||||
value = value[::-1].hex()
|
||||
if not many and key in ('_id', 'claim_id', 'sd_hash') and len(value) < 20:
|
||||
partial_id = True
|
||||
if key in ('signature_valid', 'has_source'):
|
||||
continue # handled later
|
||||
if key in TEXT_FIELDS:
|
||||
key += '.keyword'
|
||||
ops = {'<=': 'lte', '>=': 'gte', '<': 'lt', '>': 'gt'}
|
||||
if partial_id:
|
||||
query['must'].append({"prefix": {key: value}})
|
||||
elif key in RANGE_FIELDS and isinstance(value, str) and value[0] in ops:
|
||||
operator_length = 2 if value[:2] in ops else 1
|
||||
operator, value = value[:operator_length], value[operator_length:]
|
||||
if key == 'fee_amount':
|
||||
value = str(Decimal(value)*1000)
|
||||
query['must'].append({"range": {key: {ops[operator]: value}}})
|
||||
elif key in RANGE_FIELDS and isinstance(value, list) and all(v[0] in ops for v in value):
|
||||
range_constraints = []
|
||||
release_times = []
|
||||
for v in value:
|
||||
operator_length = 2 if v[:2] in ops else 1
|
||||
operator, stripped_op_v = v[:operator_length], v[operator_length:]
|
||||
if key == 'fee_amount':
|
||||
stripped_op_v = str(Decimal(stripped_op_v)*1000)
|
||||
if key == 'release_time':
|
||||
release_times.append((operator, stripped_op_v))
|
||||
else:
|
||||
range_constraints.append((operator, stripped_op_v))
|
||||
if key != 'release_time':
|
||||
query['must'].append({"range": {key: {ops[operator]: v for operator, v in range_constraints}}})
|
||||
else:
|
||||
query['must'].append(
|
||||
{"bool":
|
||||
{"should": [
|
||||
{"bool": {
|
||||
"must_not": {
|
||||
"exists": {
|
||||
"field": "release_time"
|
||||
}
|
||||
}
|
||||
}},
|
||||
{"bool": {
|
||||
"must": [
|
||||
{"exists": {"field": "release_time"}},
|
||||
{'range': {key: {ops[operator]: v for operator, v in release_times}}},
|
||||
]}},
|
||||
]}
|
||||
}
|
||||
)
|
||||
elif many:
|
||||
query['must'].append({"terms": {key: value}})
|
||||
else:
|
||||
if key == 'fee_amount':
|
||||
value = str(Decimal(value)*1000)
|
||||
query['must'].append({"term": {key: {"value": value}}})
|
||||
elif key == 'not_channel_ids':
|
||||
for channel_id in value:
|
||||
query['must_not'].append({"term": {'channel_id.keyword': channel_id}})
|
||||
query['must_not'].append({"term": {'_id': channel_id}})
|
||||
elif key == 'channel_ids':
|
||||
query['must'].append({"terms": {'channel_id.keyword': value}})
|
||||
elif key == 'claim_ids':
|
||||
query['must'].append({"terms": {'claim_id.keyword': value}})
|
||||
elif key == 'media_types':
|
||||
query['must'].append({"terms": {'media_type.keyword': value}})
|
||||
elif key == 'any_languages':
|
||||
query['must'].append({"terms": {'languages': clean_tags(value)}})
|
||||
elif key == 'any_languages':
|
||||
query['must'].append({"terms": {'languages': value}})
|
||||
elif key == 'all_languages':
|
||||
query['must'].extend([{"term": {'languages': tag}} for tag in value])
|
||||
elif key == 'any_tags':
|
||||
query['must'].append({"terms": {'tags.keyword': clean_tags(value)}})
|
||||
elif key == 'all_tags':
|
||||
query['must'].extend([{"term": {'tags.keyword': tag}} for tag in clean_tags(value)])
|
||||
elif key == 'not_tags':
|
||||
query['must_not'].extend([{"term": {'tags.keyword': tag}} for tag in clean_tags(value)])
|
||||
elif key == 'not_claim_id':
|
||||
query['must_not'].extend([{"term": {'claim_id.keyword': cid}} for cid in value])
|
||||
elif key == 'limit_claims_per_channel':
|
||||
collapse = ('channel_id.keyword', value)
|
||||
if kwargs.get('has_channel_signature'):
|
||||
query['must'].append({"exists": {"field": "signature"}})
|
||||
if 'signature_valid' in kwargs:
|
||||
query['must'].append({"term": {"is_signature_valid": bool(kwargs["signature_valid"])}})
|
||||
elif 'signature_valid' in kwargs:
|
||||
query['must'].append(
|
||||
{"bool":
|
||||
{"should": [
|
||||
{"bool": {"must_not": {"exists": {"field": "signature"}}}},
|
||||
{"bool" : {"must" : {"term": {"is_signature_valid": bool(kwargs["signature_valid"])}}}}
|
||||
]}
|
||||
}
|
||||
)
|
||||
if 'has_source' in kwargs:
|
||||
is_stream_or_repost_terms = {"terms": {"claim_type": [CLAIM_TYPES['stream'], CLAIM_TYPES['repost']]}}
|
||||
query['must'].append(
|
||||
{"bool":
|
||||
{"should": [
|
||||
{"bool": # when is_stream_or_repost AND has_source
|
||||
{"must": [
|
||||
{"match": {"has_source": kwargs['has_source']}},
|
||||
is_stream_or_repost_terms,
|
||||
]
|
||||
},
|
||||
},
|
||||
{"bool": # when not is_stream_or_repost
|
||||
{"must_not": is_stream_or_repost_terms}
|
||||
},
|
||||
{"bool": # when reposted_claim_type wouldn't have source
|
||||
{"must_not":
|
||||
[
|
||||
{"term": {"reposted_claim_type": CLAIM_TYPES['stream']}}
|
||||
],
|
||||
"must":
|
||||
[
|
||||
{"term": {"claim_type": CLAIM_TYPES['repost']}}
|
||||
]
|
||||
}
|
||||
}
|
||||
]}
|
||||
}
|
||||
)
|
||||
if kwargs.get('text'):
|
||||
query['must'].append(
|
||||
{"simple_query_string":
|
||||
{"query": kwargs["text"], "fields": [
|
||||
"claim_name^4", "channel_name^8", "title^1", "description^.5", "author^1", "tags^.5"
|
||||
]}})
|
||||
query = {
|
||||
"_source": {"excludes": ["description", "title"]},
|
||||
'query': {'bool': query},
|
||||
"sort": [],
|
||||
}
|
||||
if "limit" in kwargs:
|
||||
query["size"] = kwargs["limit"]
|
||||
if 'offset' in kwargs:
|
||||
query["from"] = kwargs["offset"]
|
||||
if 'order_by' in kwargs:
|
||||
if isinstance(kwargs["order_by"], str):
|
||||
kwargs["order_by"] = [kwargs["order_by"]]
|
||||
for value in kwargs['order_by']:
|
||||
if 'trending_group' in value:
|
||||
# fixme: trending_mixed is 0 for all records on variable decay, making sort slow.
|
||||
continue
|
||||
is_asc = value.startswith('^')
|
||||
value = value[1:] if is_asc else value
|
||||
value = REPLACEMENTS.get(value, value)
|
||||
if value in TEXT_FIELDS:
|
||||
value += '.keyword'
|
||||
query['sort'].append({value: "asc" if is_asc else "desc"})
|
||||
if collapse:
|
||||
query["collapse"] = {
|
||||
"field": collapse[0],
|
||||
"inner_hits": {
|
||||
"name": collapse[0],
|
||||
"size": collapse[1],
|
||||
"sort": query["sort"]
|
||||
}
|
||||
}
|
||||
return query
|
||||
|
||||
|
||||
def expand_result(results):
|
||||
inner_hits = []
|
||||
expanded = []
|
||||
for result in results:
|
||||
if result.get("inner_hits"):
|
||||
for _, inner_hit in result["inner_hits"].items():
|
||||
inner_hits.extend(inner_hit["hits"]["hits"])
|
||||
continue
|
||||
result = result['_source']
|
||||
result['claim_hash'] = bytes.fromhex(result['claim_id'])[::-1]
|
||||
if result['reposted_claim_id']:
|
||||
result['reposted_claim_hash'] = bytes.fromhex(result['reposted_claim_id'])[::-1]
|
||||
else:
|
||||
result['reposted_claim_hash'] = None
|
||||
result['channel_hash'] = bytes.fromhex(result['channel_id'])[::-1] if result['channel_id'] else None
|
||||
result['txo_hash'] = bytes.fromhex(result['tx_id'])[::-1] + struct.pack('<I', result['tx_nout'])
|
||||
result['tx_hash'] = bytes.fromhex(result['tx_id'])[::-1]
|
||||
result['reposted'] = result.pop('repost_count')
|
||||
result['signature_valid'] = result.pop('is_signature_valid')
|
||||
# result['normalized'] = result.pop('normalized_name')
|
||||
# if result['censoring_channel_hash']:
|
||||
# result['censoring_channel_hash'] = unhexlify(result['censoring_channel_hash'])[::-1]
|
||||
expanded.append(result)
|
||||
if inner_hits:
|
||||
return expand_result(inner_hits)
|
||||
return expanded
|
||||
|
||||
|
||||
class ResultCacheItem:
|
||||
__slots__ = '_result', 'lock', 'has_result'
|
||||
|
||||
194
hub/herald/service.py
Normal file
194
hub/herald/service.py
Normal file
|
|
@ -0,0 +1,194 @@
|
|||
import time
|
||||
import typing
|
||||
import asyncio
|
||||
from prometheus_client import Counter
|
||||
from hub import PROMETHEUS_NAMESPACE
|
||||
from hub.scribe.daemon import LBCDaemon
|
||||
from hub.herald.session import SessionManager
|
||||
from hub.herald.mempool import HubMemPool
|
||||
from hub.herald.udp import StatusServer
|
||||
from hub.herald.db import HeraldDB
|
||||
from hub.herald.search import SearchIndex
|
||||
from hub.service import BlockchainReaderService
|
||||
from hub.notifier_protocol import ElasticNotifierClientProtocol
|
||||
if typing.TYPE_CHECKING:
|
||||
from hub.herald.env import ServerEnv
|
||||
|
||||
NAMESPACE = f"{PROMETHEUS_NAMESPACE}_hub"
|
||||
|
||||
|
||||
class HubServerService(BlockchainReaderService):
|
||||
interrupt_count_metric = Counter("interrupt", "Number of interrupted queries", namespace=NAMESPACE)
|
||||
|
||||
def __init__(self, env: 'ServerEnv'):
|
||||
super().__init__(env, 'lbry-reader', thread_workers=max(1, env.max_query_workers), thread_prefix='hub-worker')
|
||||
self.env = env
|
||||
self.notifications_to_send = []
|
||||
self.mempool_notifications = set()
|
||||
self.status_server = StatusServer()
|
||||
self.daemon = LBCDaemon(env.coin, env.daemon_url, daemon_ca_path=env.daemon_ca_path) # only needed for broadcasting txs
|
||||
self.mempool = HubMemPool(self.env.coin, self.db)
|
||||
|
||||
self.search_index = SearchIndex(
|
||||
self.db, self.env.es_index_prefix, self.env.database_query_timeout,
|
||||
elastic_services=self.env.elastic_services,
|
||||
timeout_counter=self.interrupt_count_metric
|
||||
)
|
||||
|
||||
self.session_manager = SessionManager(
|
||||
env, self.db, self.mempool, self.daemon, self.search_index,
|
||||
self.shutdown_event,
|
||||
on_available_callback=self.status_server.set_available,
|
||||
on_unavailable_callback=self.status_server.set_unavailable
|
||||
)
|
||||
self.mempool.session_manager = self.session_manager
|
||||
self.es_notifications = asyncio.Queue()
|
||||
self.es_notification_client = ElasticNotifierClientProtocol(
|
||||
self.es_notifications, self.env.elastic_services
|
||||
)
|
||||
self.synchronized = asyncio.Event()
|
||||
self._es_height = None
|
||||
self._es_block_hash = None
|
||||
|
||||
def open_db(self):
|
||||
env = self.env
|
||||
self.db = HeraldDB(
|
||||
env.coin, env.db_dir, self.secondary_name, -1, env.reorg_limit,
|
||||
env.cache_all_tx_hashes, blocking_channel_ids=env.blocking_channel_ids,
|
||||
filtering_channel_ids=env.filtering_channel_ids, executor=self._executor,
|
||||
index_address_status=env.index_address_status, merkle_cache_size=env.merkle_cache_size,
|
||||
tx_cache_size=env.tx_cache_size
|
||||
)
|
||||
|
||||
def clear_caches(self):
|
||||
self.session_manager.clear_caches()
|
||||
# self.clear_search_cache()
|
||||
# self.mempool.notified_mempool_txs.clear()
|
||||
|
||||
def clear_search_cache(self):
|
||||
self.search_index.clear_caches()
|
||||
|
||||
def advance(self, height: int):
|
||||
super().advance(height)
|
||||
touched_hashXs = self.db.prefix_db.touched_hashX.get(height).touched_hashXs
|
||||
self.session_manager.update_history_caches(touched_hashXs)
|
||||
self.notifications_to_send.append((set(touched_hashXs), height))
|
||||
|
||||
def unwind(self):
|
||||
self.session_manager.hashX_raw_history_cache.clear()
|
||||
self.session_manager.hashX_history_cache.clear()
|
||||
prev_count = self.db.tx_counts.pop()
|
||||
tx_count = self.db.tx_counts[-1]
|
||||
self.db.block_hashes.pop()
|
||||
current_count = prev_count
|
||||
for _ in range(prev_count - tx_count):
|
||||
if current_count in self.session_manager.history_tx_info_cache:
|
||||
self.session_manager.history_tx_info_cache.pop(current_count)
|
||||
current_count -= 1
|
||||
if self.db._cache_all_tx_hashes:
|
||||
for _ in range(prev_count - tx_count):
|
||||
tx_hash = self.db.tx_num_mapping.pop(self.db.total_transactions.pop())
|
||||
if tx_hash in self.db.tx_cache:
|
||||
self.db.tx_cache.pop(tx_hash)
|
||||
assert len(self.db.total_transactions) == tx_count, f"{len(self.db.total_transactions)} vs {tx_count}"
|
||||
self.db.merkle_cache.clear()
|
||||
|
||||
def _detect_changes(self):
|
||||
super()._detect_changes()
|
||||
start = time.perf_counter()
|
||||
self.mempool_notifications.update(self.mempool.refresh())
|
||||
self.mempool.mempool_process_time_metric.observe(time.perf_counter() - start)
|
||||
|
||||
async def poll_for_changes(self):
|
||||
await super().poll_for_changes()
|
||||
if self.db.db_height <= 0:
|
||||
return
|
||||
self.status_server.set_height(self.db.db_height, self.db.db_tip)
|
||||
if self.notifications_to_send:
|
||||
for (touched, height) in self.notifications_to_send:
|
||||
await self.mempool.on_block(touched, height)
|
||||
self.log.info("reader advanced to %i", height)
|
||||
if self._es_height == self.db.db_height:
|
||||
self.synchronized.set()
|
||||
if self.mempool_notifications:
|
||||
await self.mempool.on_mempool(
|
||||
set(self.mempool.touched_hashXs), self.mempool_notifications, self.db.db_height
|
||||
)
|
||||
self.mempool_notifications.clear()
|
||||
self.notifications_to_send.clear()
|
||||
|
||||
async def receive_es_notifications(self, synchronized: asyncio.Event):
|
||||
synchronized.set()
|
||||
try:
|
||||
while True:
|
||||
self._es_height, self._es_block_hash = await self.es_notifications.get()
|
||||
self.clear_search_cache()
|
||||
if self.last_state and self._es_block_hash == self.last_state.tip:
|
||||
self.synchronized.set()
|
||||
self.log.info("es and reader are in sync at block %i", self.last_state.height)
|
||||
else:
|
||||
self.log.info("es and reader are not yet in sync (block %s vs %s)", self._es_height,
|
||||
self.db.db_height)
|
||||
finally:
|
||||
self.log.warning("closing es sync notification loop at %s", self._es_height)
|
||||
self.es_notification_client.close()
|
||||
|
||||
async def failover_elastic_services(self, synchronized: asyncio.Event):
|
||||
first_connect = True
|
||||
if not self.es_notification_client.lost_connection.is_set():
|
||||
synchronized.set()
|
||||
|
||||
while True:
|
||||
try:
|
||||
await self.es_notification_client.lost_connection.wait()
|
||||
if not first_connect:
|
||||
self.log.warning("lost connection to scribe-elastic-sync notifier (%s:%i)",
|
||||
self.es_notification_client.host, self.es_notification_client.port)
|
||||
await self.es_notification_client.connect()
|
||||
first_connect = False
|
||||
synchronized.set()
|
||||
self.log.info("connected to es notifier on %s:%i", self.es_notification_client.host,
|
||||
self.es_notification_client.port)
|
||||
await self.search_index.start()
|
||||
except Exception as e:
|
||||
if not isinstance(e, asyncio.CancelledError):
|
||||
self.log.warning("lost connection to scribe-elastic-sync notifier")
|
||||
await self.search_index.stop()
|
||||
self.search_index.clear_caches()
|
||||
if len(self.env.elastic_services) > 1:
|
||||
self.env.elastic_services.rotate(-1)
|
||||
self.log.warning("attempting to failover to %s:%i", self.es_notification_client.host,
|
||||
self.es_notification_client.port)
|
||||
await asyncio.sleep(1)
|
||||
else:
|
||||
self.log.warning("waiting 30s for scribe-elastic-sync notifier to become available (%s:%i)",
|
||||
self.es_notification_client.host, self.es_notification_client.port)
|
||||
await asyncio.sleep(30)
|
||||
else:
|
||||
self.log.info("stopping the notifier loop")
|
||||
raise e
|
||||
|
||||
async def start_status_server(self):
|
||||
if self.env.udp_port and int(self.env.udp_port):
|
||||
await self.status_server.start(
|
||||
0, bytes.fromhex(self.env.coin.GENESIS_HASH)[::-1], self.env.country,
|
||||
self.env.host, self.env.udp_port, self.env.allow_lan_udp
|
||||
)
|
||||
|
||||
def _iter_start_tasks(self):
|
||||
yield self.start_status_server()
|
||||
yield self.start_cancellable(self.receive_es_notifications)
|
||||
yield self.start_cancellable(self.failover_elastic_services)
|
||||
yield self.start_cancellable(self.mempool.send_notifications_forever)
|
||||
yield self.start_cancellable(self.refresh_blocks_forever)
|
||||
yield self.finished_initial_catch_up.wait()
|
||||
self.block_count_metric.set(self.last_state.height)
|
||||
yield self.start_prometheus()
|
||||
yield self.start_cancellable(self.session_manager.serve, self.mempool)
|
||||
|
||||
def _iter_stop_tasks(self):
|
||||
yield self.stop_prometheus()
|
||||
yield self.status_server.stop()
|
||||
yield self._stop_cancellable_tasks()
|
||||
yield self.session_manager.search_index.stop()
|
||||
yield self.daemon.close()
|
||||
|
|
@ -1,7 +1,8 @@
|
|||
import os
|
||||
import ssl
|
||||
import sys
|
||||
import math
|
||||
import time
|
||||
import errno
|
||||
import codecs
|
||||
import typing
|
||||
import asyncio
|
||||
|
|
@ -15,23 +16,26 @@ from contextlib import suppress
|
|||
from functools import partial
|
||||
from elasticsearch import ConnectionTimeout
|
||||
from prometheus_client import Counter, Info, Histogram, Gauge
|
||||
from scribe.schema.result import Outputs
|
||||
from scribe.error import ResolveCensoredError, TooManyClaimSearchParametersError
|
||||
from scribe import __version__, PROMETHEUS_NAMESPACE
|
||||
from scribe.hub import PROTOCOL_MIN, PROTOCOL_MAX, HUB_PROTOCOL_VERSION
|
||||
from scribe.build_info import BUILD, COMMIT_HASH, DOCKER_TAG
|
||||
from scribe.elasticsearch import SearchIndex
|
||||
from scribe.common import sha256, hash_to_hex_str, hex_str_to_hash, HASHX_LEN, version_string, formatted_time
|
||||
from scribe.common import protocol_version, RPCError, DaemonError, TaskGroup, HISTOGRAM_BUCKETS
|
||||
from scribe.hub.jsonrpc import JSONRPCAutoDetect, JSONRPCConnection, JSONRPCv2, JSONRPC
|
||||
from scribe.hub.common import BatchRequest, ProtocolError, Request, Batch, Notification
|
||||
from scribe.hub.framer import NewlineFramer
|
||||
from hub.schema.result import Outputs
|
||||
from hub.error import ResolveCensoredError, TooManyClaimSearchParametersError
|
||||
from hub import __version__, PROMETHEUS_NAMESPACE
|
||||
from hub.herald import PROTOCOL_MIN, PROTOCOL_MAX, HUB_PROTOCOL_VERSION
|
||||
from hub.build_info import BUILD, COMMIT_HASH, DOCKER_TAG
|
||||
from hub.herald.search import SearchIndex
|
||||
from hub.common import sha256, hash_to_hex_str, hex_str_to_hash, HASHX_LEN, version_string, formatted_time, SIZE_BUCKETS
|
||||
from hub.common import protocol_version, RPCError, DaemonError, TaskGroup, HISTOGRAM_BUCKETS, asyncify_for_loop
|
||||
from hub.common import LRUCacheWithMetrics, LFUCacheWithMetrics, LargestValueCache
|
||||
from hub.herald.jsonrpc import JSONRPCAutoDetect, JSONRPCConnection, JSONRPCv2, JSONRPC
|
||||
from hub.herald.common import BatchRequest, ProtocolError, Request, Batch, Notification
|
||||
from hub.herald.framer import NewlineFramer
|
||||
if typing.TYPE_CHECKING:
|
||||
from scribe.db import HubDB
|
||||
from scribe.env import Env
|
||||
from scribe.blockchain.daemon import LBCDaemon
|
||||
from scribe.hub.mempool import HubMemPool
|
||||
from hub.db import SecondaryDB
|
||||
from hub.herald.env import ServerEnv
|
||||
from hub.scribe.daemon import LBCDaemon
|
||||
from hub.herald.mempool import HubMemPool
|
||||
|
||||
PYTHON_VERSION = sys.version_info.major, sys.version_info.minor
|
||||
TypedDict = dict if PYTHON_VERSION < (3, 8) else typing.TypedDict
|
||||
BAD_REQUEST = 1
|
||||
DAEMON_ERROR = 2
|
||||
|
||||
|
|
@ -42,6 +46,11 @@ SignatureInfo = namedtuple('SignatureInfo', 'min_args max_args '
|
|||
'required_names other_names')
|
||||
|
||||
|
||||
class CachedAddressHistoryItem(TypedDict):
|
||||
tx_hash: str
|
||||
height: int
|
||||
|
||||
|
||||
def scripthash_to_hashX(scripthash: str) -> bytes:
|
||||
try:
|
||||
bin_hash = hex_str_to_hash(scripthash)
|
||||
|
|
@ -128,12 +137,11 @@ class SessionManager:
|
|||
session_count_metric = Gauge("session_count", "Number of connected client sessions", namespace=NAMESPACE,
|
||||
labelnames=("version",))
|
||||
request_count_metric = Counter("requests_count", "Number of requests received", namespace=NAMESPACE,
|
||||
labelnames=("method", "version"))
|
||||
labelnames=("method",))
|
||||
tx_request_count_metric = Counter("requested_transaction", "Number of transactions requested", namespace=NAMESPACE)
|
||||
tx_replied_count_metric = Counter("replied_transaction", "Number of transactions responded", namespace=NAMESPACE)
|
||||
urls_to_resolve_count_metric = Counter("urls_to_resolve", "Number of urls to resolve", namespace=NAMESPACE)
|
||||
resolved_url_count_metric = Counter("resolved_url", "Number of resolved urls", namespace=NAMESPACE)
|
||||
interrupt_count_metric = Counter("interrupt", "Number of interrupted queries", namespace=NAMESPACE)
|
||||
db_operational_error_metric = Counter(
|
||||
"operational_error", "Number of queries that raised operational errors", namespace=NAMESPACE
|
||||
)
|
||||
|
|
@ -146,7 +154,6 @@ class SessionManager:
|
|||
pending_query_metric = Gauge(
|
||||
"pending_queries_count", "Number of pending and running sqlite queries", namespace=NAMESPACE
|
||||
)
|
||||
|
||||
client_version_metric = Counter(
|
||||
"clients", "Number of connections received per client version",
|
||||
namespace=NAMESPACE, labelnames=("version",)
|
||||
|
|
@ -155,6 +162,14 @@ class SessionManager:
|
|||
"address_history", "Time to fetch an address history",
|
||||
namespace=NAMESPACE, buckets=HISTOGRAM_BUCKETS
|
||||
)
|
||||
address_subscription_metric = Gauge(
|
||||
"address_subscriptions", "Number of subscribed addresses",
|
||||
namespace=NAMESPACE
|
||||
)
|
||||
address_history_size_metric = Histogram(
|
||||
"history_size", "Sizes of histories for subscribed addresses",
|
||||
namespace=NAMESPACE, buckets=SIZE_BUCKETS
|
||||
)
|
||||
notifications_in_flight_metric = Gauge(
|
||||
"notifications_in_flight", "Count of notifications in flight",
|
||||
namespace=NAMESPACE
|
||||
|
|
@ -164,8 +179,8 @@ class SessionManager:
|
|||
namespace=NAMESPACE, buckets=HISTOGRAM_BUCKETS
|
||||
)
|
||||
|
||||
def __init__(self, env: 'Env', db: 'HubDB', mempool: 'HubMemPool',
|
||||
daemon: 'LBCDaemon', shutdown_event: asyncio.Event,
|
||||
def __init__(self, env: 'ServerEnv', db: 'SecondaryDB', mempool: 'HubMemPool',
|
||||
daemon: 'LBCDaemon', search_index: 'SearchIndex', shutdown_event: asyncio.Event,
|
||||
on_available_callback: typing.Callable[[], None], on_unavailable_callback: typing.Callable[[], None]):
|
||||
env.max_send = max(350000, env.max_send)
|
||||
self.env = env
|
||||
|
|
@ -174,6 +189,7 @@ class SessionManager:
|
|||
self.on_unavailable_callback = on_unavailable_callback
|
||||
self.daemon = daemon
|
||||
self.mempool = mempool
|
||||
self.search_index = search_index
|
||||
self.shutdown_event = shutdown_event
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.servers: typing.Dict[str, asyncio.AbstractServer] = {}
|
||||
|
|
@ -183,32 +199,65 @@ class SessionManager:
|
|||
self.cur_group = SessionGroup(0)
|
||||
self.txs_sent = 0
|
||||
self.start_time = time.time()
|
||||
self.history_cache = {}
|
||||
self.resolve_outputs_cache = {}
|
||||
self.resolve_cache = {}
|
||||
self.resolve_cache = LRUCacheWithMetrics(
|
||||
env.resolved_url_cache_size, metric_name='resolved_url', namespace=NAMESPACE
|
||||
)
|
||||
self.notified_height: typing.Optional[int] = None
|
||||
# Cache some idea of room to avoid recounting on each subscription
|
||||
self.subs_room = 0
|
||||
|
||||
self.protocol_class = LBRYElectrumX
|
||||
self.session_event = Event()
|
||||
|
||||
# Search index
|
||||
self.search_index = SearchIndex(
|
||||
self.db, self.env.es_index_prefix, self.env.database_query_timeout,
|
||||
elastic_host=env.elastic_host, elastic_port=env.elastic_port
|
||||
)
|
||||
self.running = False
|
||||
# hashX: List[int]
|
||||
self.hashX_raw_history_cache = LFUCacheWithMetrics(env.hashX_history_cache_size, metric_name='raw_history', namespace=NAMESPACE)
|
||||
# hashX: List[CachedAddressHistoryItem]
|
||||
self.hashX_history_cache = LargestValueCache(env.largest_hashX_history_cache_size)
|
||||
# tx_num: Tuple[txid, height]
|
||||
self.history_tx_info_cache = LFUCacheWithMetrics(env.history_tx_cache_size, metric_name='history_tx', namespace=NAMESPACE)
|
||||
|
||||
def clear_caches(self):
|
||||
self.history_cache.clear()
|
||||
self.resolve_outputs_cache.clear()
|
||||
self.resolve_cache.clear()
|
||||
|
||||
def update_history_caches(self, touched_hashXs: typing.List[bytes]):
|
||||
update_history_cache = {}
|
||||
for hashX in set(touched_hashXs):
|
||||
history_tx_nums = None
|
||||
# if the history is the raw_history_cache, update it
|
||||
# TODO: use a reversed iterator for this instead of rescanning it all
|
||||
if hashX in self.hashX_raw_history_cache:
|
||||
self.hashX_raw_history_cache[hashX] = history_tx_nums = self.db._read_history(hashX, None)
|
||||
# if it's in hashX_history_cache, prepare to update it in a batch
|
||||
if hashX in self.hashX_history_cache:
|
||||
full_cached = self.hashX_history_cache[hashX]
|
||||
if history_tx_nums is None:
|
||||
history_tx_nums = self.db._read_history(hashX, None)
|
||||
new_txs = history_tx_nums[len(full_cached):]
|
||||
update_history_cache[hashX] = full_cached, new_txs
|
||||
if update_history_cache:
|
||||
# get the set of new tx nums that were touched in all of the new histories to be cached
|
||||
total_tx_nums = set()
|
||||
for _, new_txs in update_history_cache.values():
|
||||
total_tx_nums.update(new_txs)
|
||||
total_tx_nums = list(total_tx_nums)
|
||||
# collect the total new tx infos
|
||||
referenced_new_txs = {
|
||||
tx_num: (CachedAddressHistoryItem(
|
||||
tx_hash=tx_hash[::-1].hex(), height=bisect_right(self.db.tx_counts, tx_num)
|
||||
)) for tx_num, tx_hash in zip(total_tx_nums, self.db._get_tx_hashes(total_tx_nums))
|
||||
}
|
||||
# update the cached history lists
|
||||
get_referenced = referenced_new_txs.__getitem__
|
||||
for hashX, (full, new_txs) in update_history_cache.items():
|
||||
append_to_full = full.append
|
||||
for tx_num in new_txs:
|
||||
append_to_full(get_referenced(tx_num))
|
||||
|
||||
async def _start_server(self, kind, *args, **kw_args):
|
||||
loop = asyncio.get_event_loop()
|
||||
|
||||
if kind == 'TCP':
|
||||
protocol_class = LBRYElectrumX
|
||||
protocol_class = self.protocol_class
|
||||
else:
|
||||
raise ValueError(kind)
|
||||
protocol_factory = partial(protocol_class, self, kind)
|
||||
|
|
@ -216,9 +265,11 @@ class SessionManager:
|
|||
host, port = args[:2]
|
||||
try:
|
||||
self.servers[kind] = await loop.create_server(protocol_factory, *args, **kw_args)
|
||||
except OSError as e: # don't suppress CancelledError
|
||||
self.logger.error(f'{kind} server failed to listen on {host}:'
|
||||
f'{port:d} :{e!r}')
|
||||
except Exception as e:
|
||||
if not isinstance(e, asyncio.CancelledError):
|
||||
self.logger.error(f'{kind} server failed to listen on '
|
||||
f'{host}:{port:d} : {e!r}')
|
||||
raise
|
||||
else:
|
||||
self.logger.info(f'{kind} server listening on {host}:{port:d}')
|
||||
|
||||
|
|
@ -228,12 +279,19 @@ class SessionManager:
|
|||
"""
|
||||
env = self.env
|
||||
host = env.cs_host()
|
||||
if env.tcp_port is not None:
|
||||
await self._start_server('TCP', host, env.tcp_port)
|
||||
if env.ssl_port is not None:
|
||||
sslc = ssl.SSLContext(ssl.PROTOCOL_TLS)
|
||||
sslc.load_cert_chain(env.ssl_certfile, keyfile=env.ssl_keyfile)
|
||||
await self._start_server('SSL', host, env.ssl_port, ssl=sslc)
|
||||
if env.tcp_port is None:
|
||||
return
|
||||
started = False
|
||||
while not started:
|
||||
try:
|
||||
await self._start_server('TCP', host, env.tcp_port)
|
||||
started = True
|
||||
except OSError as e:
|
||||
if e.errno is errno.EADDRINUSE:
|
||||
await asyncio.sleep(3)
|
||||
continue
|
||||
raise
|
||||
|
||||
|
||||
async def _close_servers(self, kinds):
|
||||
"""Close the servers of the given kinds (TCP etc.)."""
|
||||
|
|
@ -596,25 +654,57 @@ class SessionManager:
|
|||
self.txs_sent += 1
|
||||
return hex_hash
|
||||
|
||||
async def limited_history(self, hashX):
|
||||
"""A caching layer."""
|
||||
if hashX not in self.history_cache:
|
||||
# History DoS limit. Each element of history is about 99
|
||||
# bytes when encoded as JSON. This limits resource usage
|
||||
# on bloated history requests, and uses a smaller divisor
|
||||
# so large requests are logged before refusing them.
|
||||
limit = self.env.max_send // 97
|
||||
self.history_cache[hashX] = await self.db.limited_history(hashX, limit=limit)
|
||||
return self.history_cache[hashX]
|
||||
async def _cached_raw_history(self, hashX: bytes, limit: typing.Optional[int] = None):
|
||||
tx_nums = self.hashX_raw_history_cache.get(hashX)
|
||||
if tx_nums is None:
|
||||
self.hashX_raw_history_cache[hashX] = tx_nums = await self.db.read_history(hashX, limit)
|
||||
return tx_nums
|
||||
|
||||
async def cached_confirmed_history(self, hashX: bytes,
|
||||
limit: typing.Optional[int] = None) -> typing.List[CachedAddressHistoryItem]:
|
||||
cached_full_history = self.hashX_history_cache.get(hashX)
|
||||
# return the cached history
|
||||
if cached_full_history is not None:
|
||||
self.address_history_size_metric.observe(len(cached_full_history))
|
||||
return cached_full_history
|
||||
# return the history and update the caches
|
||||
tx_nums = await self._cached_raw_history(hashX, limit)
|
||||
needed_tx_infos = []
|
||||
append_needed_tx_info = needed_tx_infos.append
|
||||
tx_infos = {}
|
||||
for cnt, tx_num in enumerate(tx_nums): # determine which tx_hashes are cached and which we need to look up
|
||||
cached = self.history_tx_info_cache.get(tx_num)
|
||||
if cached is not None:
|
||||
tx_infos[tx_num] = cached
|
||||
else:
|
||||
append_needed_tx_info(tx_num)
|
||||
if cnt % 1000 == 0:
|
||||
await asyncio.sleep(0)
|
||||
if needed_tx_infos: # request all the needed tx hashes in one batch, cache the txids and heights
|
||||
for cnt, (tx_num, tx_hash) in enumerate(zip(needed_tx_infos, await self.db.get_tx_hashes(needed_tx_infos))):
|
||||
hist = CachedAddressHistoryItem(tx_hash=tx_hash[::-1].hex(), height=bisect_right(self.db.tx_counts, tx_num))
|
||||
tx_infos[tx_num] = self.history_tx_info_cache[tx_num] = hist
|
||||
if cnt % 1000 == 0:
|
||||
await asyncio.sleep(0)
|
||||
# ensure the ordering of the txs
|
||||
history = []
|
||||
history_append = history.append
|
||||
for cnt, tx_num in enumerate(tx_nums):
|
||||
history_append(tx_infos[tx_num])
|
||||
if cnt % 1000 == 0:
|
||||
await asyncio.sleep(0)
|
||||
self.hashX_history_cache[hashX] = history
|
||||
self.address_history_size_metric.observe(len(history))
|
||||
return history
|
||||
|
||||
def _notify_peer(self, peer):
|
||||
notify_tasks = [
|
||||
session.send_notification('blockchain.peers.subscribe', [peer])
|
||||
for session in self.sessions.values() if session.subscribe_peers
|
||||
]
|
||||
if notify_tasks:
|
||||
self.logger.info(f'notify {len(notify_tasks)} sessions of new peers')
|
||||
asyncio.create_task(asyncio.wait(notify_tasks))
|
||||
notify_count = 0
|
||||
for session in self.sessions.values():
|
||||
if session.subscribe_peers:
|
||||
notify_count += 1
|
||||
session.send_notification('blockchain.peers.subscribe', [peer])
|
||||
if notify_count:
|
||||
self.logger.info(f'notify {notify_count} sessions of new peers')
|
||||
|
||||
def add_session(self, session):
|
||||
self.sessions[id(session)] = session
|
||||
|
|
@ -627,6 +717,7 @@ class SessionManager:
|
|||
def remove_session(self, session):
|
||||
"""Remove a session from our sessions list if there."""
|
||||
session_id = id(session)
|
||||
self.address_subscription_metric.dec(len(session.hashX_subs))
|
||||
for hashX in session.hashX_subs:
|
||||
sessions = self.hashx_subscriptions_by_session[hashX]
|
||||
sessions.remove(session_id)
|
||||
|
|
@ -648,9 +739,9 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
MAX_CHUNK_SIZE = 40960
|
||||
session_counter = itertools.count()
|
||||
RESPONSE_TIMES = Histogram("response_time", "Response times", namespace=NAMESPACE,
|
||||
labelnames=("method", "version"), buckets=HISTOGRAM_BUCKETS)
|
||||
labelnames=("method",), buckets=HISTOGRAM_BUCKETS)
|
||||
NOTIFICATION_COUNT = Counter("notification", "Number of notifications sent (for subscriptions)",
|
||||
namespace=NAMESPACE, labelnames=("method", "version"))
|
||||
namespace=NAMESPACE, labelnames=("method",))
|
||||
REQUEST_ERRORS_COUNT = Counter(
|
||||
"request_error", "Number of requests that returned errors", namespace=NAMESPACE,
|
||||
labelnames=("method", "version")
|
||||
|
|
@ -698,7 +789,6 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
|
||||
self.kind = kind # 'RPC', 'TCP' etc.
|
||||
self.coin = self.env.coin
|
||||
self.anon_logs = self.env.anon_logs
|
||||
self.txs_sent = 0
|
||||
self.log_me = False
|
||||
self.daemon_request = self.session_manager.daemon_request
|
||||
|
|
@ -785,19 +875,6 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
def default_framer(self):
|
||||
return NewlineFramer(self.env.max_receive)
|
||||
|
||||
def peer_address_str(self, *, for_log=True):
|
||||
"""Returns the peer's IP address and port as a human-readable
|
||||
string, respecting anon logs if the output is for a log."""
|
||||
if for_log and self.anon_logs:
|
||||
return 'xx.xx.xx.xx:xx'
|
||||
if not self._address:
|
||||
return 'unknown'
|
||||
ip_addr_str, port = self._address[:2]
|
||||
if ':' in ip_addr_str:
|
||||
return f'[{ip_addr_str}]:{port}'
|
||||
else:
|
||||
return f'{ip_addr_str}:{port}'
|
||||
|
||||
def toggle_logging(self):
|
||||
self.log_me = not self.log_me
|
||||
|
||||
|
|
@ -811,8 +888,6 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
"""Handle an incoming request. ElectrumX doesn't receive
|
||||
notifications from client sessions.
|
||||
"""
|
||||
self.session_manager.request_count_metric.labels(method=request.method, version=self.client_version).inc()
|
||||
|
||||
if isinstance(request, Request):
|
||||
method = request.method
|
||||
if method == 'blockchain.block.get_chunk':
|
||||
|
|
@ -891,6 +966,7 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
raise RPCError(JSONRPC.METHOD_NOT_FOUND, f'unknown method "{method}"')
|
||||
else:
|
||||
raise ValueError
|
||||
self.session_manager.request_count_metric.labels(method=request.method).inc()
|
||||
if isinstance(request.args, dict):
|
||||
return await coro(**request.args)
|
||||
return await coro(*request.args)
|
||||
|
|
@ -999,10 +1075,7 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
'internal server error')
|
||||
if isinstance(request, Request):
|
||||
message = request.send_result(result)
|
||||
self.RESPONSE_TIMES.labels(
|
||||
method=request.method,
|
||||
version=self.client_version
|
||||
).observe(time.perf_counter() - start)
|
||||
self.RESPONSE_TIMES.labels(method=request.method).observe(time.perf_counter() - start)
|
||||
if message:
|
||||
await self._send_message(message)
|
||||
if isinstance(result, Exception):
|
||||
|
|
@ -1029,26 +1102,29 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
raise result
|
||||
return result
|
||||
|
||||
async def send_notification(self, method, args=()) -> bool:
|
||||
async def _send_notification(self, method, args=()) -> bool:
|
||||
"""Send an RPC notification over the network."""
|
||||
message = self.connection.send_notification(Notification(method, args))
|
||||
self.NOTIFICATION_COUNT.labels(method=method, version=self.client_version).inc()
|
||||
self.NOTIFICATION_COUNT.labels(method=method).inc()
|
||||
try:
|
||||
await self._send_message(message)
|
||||
return True
|
||||
except asyncio.TimeoutError:
|
||||
self.logger.info("timeout sending address notification to %s", self.peer_address_str(for_log=True))
|
||||
self.logger.info(f"timeout sending address notification to {self._address[0]}:{self._address[1]}")
|
||||
self.abort()
|
||||
return False
|
||||
|
||||
async def send_notifications(self, notifications) -> bool:
|
||||
def send_notification(self, method, args=()):
|
||||
self._task_group.add(self._send_notification(method, args))
|
||||
|
||||
async def _send_notifications(self, notifications) -> bool:
|
||||
"""Send an RPC notification over the network."""
|
||||
message, _ = self.connection.send_batch(notifications)
|
||||
try:
|
||||
await self._send_message(message)
|
||||
return True
|
||||
except asyncio.TimeoutError:
|
||||
self.logger.info("timeout sending address notification to %s", self.peer_address_str(for_log=True))
|
||||
self.logger.info(f"timeout sending address notification to {self._address[0]}:{self._address[1]}")
|
||||
self.abort()
|
||||
return False
|
||||
|
||||
|
|
@ -1078,7 +1154,7 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
"""Return the server features dictionary."""
|
||||
min_str, max_str = cls.protocol_min_max_strings()
|
||||
cls.cached_server_features.update({
|
||||
'hosts': env.hosts_dict(),
|
||||
'hosts': {},
|
||||
'pruning': None,
|
||||
'server_version': cls.version,
|
||||
'protocol_min': min_str,
|
||||
|
|
@ -1107,35 +1183,53 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
return len(self.hashX_subs)
|
||||
|
||||
async def get_hashX_status(self, hashX: bytes):
|
||||
return await self.loop.run_in_executor(self.db._executor, self.db.get_hashX_status, hashX)
|
||||
if self.env.index_address_status:
|
||||
return await self.db.get_hashX_status(hashX)
|
||||
history = ''.join(
|
||||
f"{tx_hash[::-1].hex()}:{height:d}:"
|
||||
for tx_hash, height in await self.db.limited_history(hashX, limit=None)
|
||||
) + self.mempool.mempool_history(hashX)
|
||||
if not history:
|
||||
return
|
||||
status = sha256(history.encode())
|
||||
return status.hex()
|
||||
|
||||
async def send_history_notifications(self, *hashXes: typing.Iterable[bytes]):
|
||||
async def get_hashX_statuses(self, hashXes: typing.List[bytes]):
|
||||
if self.env.index_address_status:
|
||||
return await self.db.get_hashX_statuses(hashXes)
|
||||
return [await self.get_hashX_status(hashX) for hashX in hashXes]
|
||||
|
||||
async def _send_history_notifications(self, hashXes: typing.List[bytes]):
|
||||
notifications = []
|
||||
for hashX in hashXes:
|
||||
start = time.perf_counter()
|
||||
statuses = await self.get_hashX_statuses(hashXes)
|
||||
duration = time.perf_counter() - start
|
||||
self.session_manager.address_history_metric.observe(duration)
|
||||
start = time.perf_counter()
|
||||
scripthash_notifications = 0
|
||||
address_notifications = 0
|
||||
for hashX, status in zip(hashXes, statuses):
|
||||
alias = self.hashX_subs[hashX]
|
||||
if len(alias) == 64:
|
||||
method = 'blockchain.scripthash.subscribe'
|
||||
scripthash_notifications += 1
|
||||
else:
|
||||
method = 'blockchain.address.subscribe'
|
||||
start = time.perf_counter()
|
||||
status = await self.get_hashX_status(hashX)
|
||||
duration = time.perf_counter() - start
|
||||
self.session_manager.address_history_metric.observe(duration)
|
||||
notifications.append((method, (alias, status)))
|
||||
if duration > 30:
|
||||
self.logger.warning("slow history notification (%s) for '%s'", duration, alias)
|
||||
|
||||
start = time.perf_counter()
|
||||
self.session_manager.notifications_in_flight_metric.inc()
|
||||
for method, args in notifications:
|
||||
self.NOTIFICATION_COUNT.labels(method=method, version=self.client_version).inc()
|
||||
address_notifications += 1
|
||||
notifications.append(Notification(method, (alias, status)))
|
||||
if scripthash_notifications:
|
||||
self.NOTIFICATION_COUNT.labels(method='blockchain.scripthash.subscribe',).inc(scripthash_notifications)
|
||||
if address_notifications:
|
||||
self.NOTIFICATION_COUNT.labels(method='blockchain.address.subscribe', ).inc(address_notifications)
|
||||
self.session_manager.notifications_in_flight_metric.inc(len(notifications))
|
||||
try:
|
||||
await self.send_notifications(
|
||||
Batch([Notification(method, (alias, status)) for (method, (alias, status)) in notifications])
|
||||
)
|
||||
await self._send_notifications(Batch(notifications))
|
||||
self.session_manager.notifications_sent_metric.observe(time.perf_counter() - start)
|
||||
finally:
|
||||
self.session_manager.notifications_in_flight_metric.dec()
|
||||
self.session_manager.notifications_in_flight_metric.dec(len(notifications))
|
||||
|
||||
def send_history_notifications(self, hashXes: typing.List[bytes]):
|
||||
self._task_group.add(self._send_history_notifications(hashXes))
|
||||
|
||||
# def get_metrics_or_placeholder_for_api(self, query_name):
|
||||
# """ Do not hold on to a reference to the metrics
|
||||
|
|
@ -1184,7 +1278,7 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
kwargs['channel_id'] = channel_claim.claim_hash.hex()
|
||||
return await self.session_manager.search_index.cached_search(kwargs)
|
||||
except ConnectionTimeout:
|
||||
self.session_manager.interrupt_count_metric.inc()
|
||||
self.session_manager.search_index.timeout_counter.inc()
|
||||
raise RPCError(JSONRPC.QUERY_TIMEOUT, 'query timed out')
|
||||
except TooManyClaimSearchParametersError as err:
|
||||
await asyncio.sleep(2)
|
||||
|
|
@ -1195,22 +1289,26 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
self.session_manager.pending_query_metric.dec()
|
||||
self.session_manager.executor_time_metric.observe(time.perf_counter() - start)
|
||||
|
||||
async def _cached_resolve_url(self, url):
|
||||
if url not in self.session_manager.resolve_cache:
|
||||
self.session_manager.resolve_cache[url] = await self.loop.run_in_executor(self.db._executor, self.db._resolve, url)
|
||||
return self.session_manager.resolve_cache[url]
|
||||
|
||||
async def claimtrie_resolve(self, *urls) -> str:
|
||||
sorted_urls = tuple(sorted(urls))
|
||||
self.session_manager.urls_to_resolve_count_metric.inc(len(sorted_urls))
|
||||
self.session_manager.urls_to_resolve_count_metric.inc(len(urls))
|
||||
try:
|
||||
if sorted_urls in self.session_manager.resolve_outputs_cache:
|
||||
return self.session_manager.resolve_outputs_cache[sorted_urls]
|
||||
rows, extra = [], []
|
||||
resolved = {}
|
||||
needed = defaultdict(list)
|
||||
for idx, url in enumerate(urls):
|
||||
cached = self.session_manager.resolve_cache.get(url)
|
||||
if cached:
|
||||
stream, channel, repost, reposted_channel = cached
|
||||
resolved[url] = stream, channel, repost, reposted_channel
|
||||
else:
|
||||
needed[url].append(idx)
|
||||
if needed:
|
||||
resolved_needed = await self.db.batch_resolve_urls(list(needed))
|
||||
for url, resolve_result in resolved_needed.items():
|
||||
self.session_manager.resolve_cache[url] = resolve_result
|
||||
resolved.update(resolved_needed)
|
||||
for url in urls:
|
||||
if url not in self.session_manager.resolve_cache:
|
||||
self.session_manager.resolve_cache[url] = await self._cached_resolve_url(url)
|
||||
stream, channel, repost, reposted_channel = self.session_manager.resolve_cache[url]
|
||||
(stream, channel, repost, reposted_channel) = resolved[url]
|
||||
if isinstance(channel, ResolveCensoredError):
|
||||
rows.append(channel)
|
||||
extra.append(channel.censor_row)
|
||||
|
|
@ -1225,28 +1323,22 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
extra.append(reposted_channel.censor_row)
|
||||
elif channel and not stream:
|
||||
rows.append(channel)
|
||||
# print("resolved channel", channel.name.decode())
|
||||
if repost:
|
||||
extra.append(repost)
|
||||
if reposted_channel:
|
||||
extra.append(reposted_channel)
|
||||
elif stream:
|
||||
# print("resolved stream", stream.name.decode())
|
||||
rows.append(stream)
|
||||
if channel:
|
||||
# print("and channel", channel.name.decode())
|
||||
extra.append(channel)
|
||||
if repost:
|
||||
extra.append(repost)
|
||||
if reposted_channel:
|
||||
extra.append(reposted_channel)
|
||||
await asyncio.sleep(0)
|
||||
self.session_manager.resolve_outputs_cache[sorted_urls] = result = await self.loop.run_in_executor(
|
||||
None, Outputs.to_base64, rows, extra
|
||||
)
|
||||
return result
|
||||
|
||||
return Outputs.to_base64(rows, extra)
|
||||
finally:
|
||||
self.session_manager.resolved_url_count_metric.inc(len(sorted_urls))
|
||||
self.session_manager.resolved_url_count_metric.inc(len(urls))
|
||||
|
||||
async def get_server_height(self):
|
||||
return self.db.db_height
|
||||
|
|
@ -1360,6 +1452,8 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
sessions.remove(id(self))
|
||||
except KeyError:
|
||||
pass
|
||||
else:
|
||||
self.session_manager.address_subscription_metric.dec()
|
||||
if not sessions:
|
||||
self.hashX_subs.pop(hashX, None)
|
||||
|
||||
|
|
@ -1396,11 +1490,12 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
address: the address to subscribe to"""
|
||||
if len(addresses) > 1000:
|
||||
raise RPCError(BAD_REQUEST, f'too many addresses in subscription request: {len(addresses)}')
|
||||
results = []
|
||||
for address in addresses:
|
||||
results.append(await self.hashX_subscribe(self.address_to_hashX(address), address))
|
||||
await asyncio.sleep(0)
|
||||
return results
|
||||
hashXes = [item async for item in asyncify_for_loop((self.address_to_hashX(address) for address in addresses), 100)]
|
||||
for hashX, alias in zip(hashXes, addresses):
|
||||
self.hashX_subs[hashX] = alias
|
||||
self.session_manager.hashx_subscriptions_by_session[hashX].add(id(self))
|
||||
self.session_manager.address_subscription_metric.inc(len(addresses))
|
||||
return await self.get_hashX_statuses(hashXes)
|
||||
|
||||
async def address_unsubscribe(self, address):
|
||||
"""Unsubscribe an address.
|
||||
|
|
@ -1430,10 +1525,8 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
|
||||
async def confirmed_and_unconfirmed_history(self, hashX):
|
||||
# Note history is ordered but unconfirmed is unordered in e-s
|
||||
history = await self.session_manager.limited_history(hashX)
|
||||
conf = [{'tx_hash': hash_to_hex_str(tx_hash), 'height': height}
|
||||
for tx_hash, height in history]
|
||||
return conf + self.unconfirmed_history(hashX)
|
||||
history = await self.session_manager.cached_confirmed_history(hashX)
|
||||
return history + self.unconfirmed_history(hashX)
|
||||
|
||||
async def scripthash_get_history(self, scripthash):
|
||||
"""Return the confirmed and unconfirmed history of a scripthash."""
|
||||
|
|
@ -1455,6 +1548,7 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
|
||||
scripthash: the SHA256 hash of the script to subscribe to"""
|
||||
hashX = scripthash_to_hashX(scripthash)
|
||||
self.session_manager.address_subscription_metric.inc()
|
||||
return await self.hashX_subscribe(hashX, scripthash)
|
||||
|
||||
async def scripthash_unsubscribe(self, scripthash: str):
|
||||
|
|
@ -1572,7 +1666,8 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
async def relayfee(self):
|
||||
"""The minimum fee a low-priority tx must pay in order to be accepted
|
||||
to the daemon's memory pool."""
|
||||
return await self.daemon_request('relayfee')
|
||||
# return await self.daemon_request('relayfee')
|
||||
return 0.00001
|
||||
|
||||
async def estimatefee(self, number):
|
||||
"""The estimated transaction fee per kilobyte to be paid for a
|
||||
|
|
@ -1580,8 +1675,9 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
|
||||
number: the number of blocks
|
||||
"""
|
||||
number = non_negative_integer(number)
|
||||
return await self.daemon_request('estimatefee', number)
|
||||
# number = non_negative_integer(number)
|
||||
# return await self.daemon_request('estimatefee', number)
|
||||
return 0.00014601
|
||||
|
||||
async def ping(self):
|
||||
"""Serves as a connection keep-alive mechanism and for the client to
|
||||
|
|
@ -1668,14 +1764,15 @@ class LBRYElectrumX(asyncio.Protocol):
|
|||
verbose: passed on to the daemon
|
||||
"""
|
||||
assert_tx_hash(txid)
|
||||
if verbose not in (True, False):
|
||||
raise RPCError(BAD_REQUEST, f'"verbose" must be a boolean')
|
||||
verbose = bool(verbose)
|
||||
tx_hash_bytes = bytes.fromhex(txid)[::-1]
|
||||
|
||||
raw_tx = await asyncio.get_event_loop().run_in_executor(None, self.db.get_raw_tx, tx_hash_bytes)
|
||||
if raw_tx:
|
||||
return raw_tx.hex()
|
||||
return RPCError("No such mempool or blockchain transaction.")
|
||||
if not verbose:
|
||||
return raw_tx.hex()
|
||||
return self.coin.transaction(raw_tx).as_dict(self.coin)
|
||||
return RPCError(BAD_REQUEST, "No such mempool or blockchain transaction.")
|
||||
|
||||
def _get_merkle_branch(self, tx_hashes, tx_pos):
|
||||
"""Return a merkle branch to a transaction.
|
||||
|
|
@ -3,8 +3,8 @@ import struct
|
|||
from time import perf_counter
|
||||
import logging
|
||||
from typing import Optional, Tuple, NamedTuple
|
||||
from scribe.schema.attrs import country_str_to_int, country_int_to_str
|
||||
from scribe.common import LRUCache, is_valid_public_ipv4
|
||||
from hub.schema.attrs import country_str_to_int, country_int_to_str
|
||||
from hub.common import LRUCache, is_valid_public_ipv4
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
|
@ -2,6 +2,7 @@ import typing
|
|||
import struct
|
||||
import asyncio
|
||||
import logging
|
||||
from typing import Deque, Tuple
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
|
@ -31,52 +32,39 @@ class ElasticNotifierProtocol(asyncio.Protocol):
|
|||
class ElasticNotifierClientProtocol(asyncio.Protocol):
|
||||
"""notifies the reader when ES has written updates"""
|
||||
|
||||
def __init__(self, notifications: asyncio.Queue, host: str, port: int):
|
||||
def __init__(self, notifications: asyncio.Queue, notifier_hosts: Deque[Tuple[Tuple[str, int], Tuple[str, int]]]):
|
||||
assert len(notifier_hosts) > 0, 'no elastic notifier clients given'
|
||||
self.notifications = notifications
|
||||
self.transport: typing.Optional[asyncio.Transport] = None
|
||||
self.host = host
|
||||
self.port = port
|
||||
self._lost_connection = asyncio.Event()
|
||||
self._lost_connection.set()
|
||||
self._notifier_hosts = notifier_hosts
|
||||
self.lost_connection = asyncio.Event()
|
||||
self.lost_connection.set()
|
||||
|
||||
@property
|
||||
def host(self):
|
||||
return self._notifier_hosts[0][1][0]
|
||||
|
||||
@property
|
||||
def port(self):
|
||||
return self._notifier_hosts[0][1][1]
|
||||
|
||||
async def connect(self):
|
||||
if self._lost_connection.is_set():
|
||||
if self.lost_connection.is_set():
|
||||
await asyncio.get_event_loop().create_connection(
|
||||
lambda: self, self.host, self.port
|
||||
)
|
||||
|
||||
async def maintain_connection(self, synchronized: asyncio.Event):
|
||||
first_connect = True
|
||||
if not self._lost_connection.is_set():
|
||||
synchronized.set()
|
||||
while True:
|
||||
try:
|
||||
await self._lost_connection.wait()
|
||||
if not first_connect:
|
||||
log.warning("lost connection to scribe-elastic-sync notifier")
|
||||
await self.connect()
|
||||
first_connect = False
|
||||
synchronized.set()
|
||||
log.info("connected to es notifier")
|
||||
except Exception as e:
|
||||
if not isinstance(e, asyncio.CancelledError):
|
||||
log.warning("waiting 30s for scribe-elastic-sync notifier to become available (%s:%i)", self.host, self.port)
|
||||
await asyncio.sleep(30)
|
||||
else:
|
||||
log.info("stopping the notifier loop")
|
||||
raise e
|
||||
|
||||
def close(self):
|
||||
if self.transport and not self.transport.is_closing():
|
||||
self.transport.close()
|
||||
|
||||
def connection_made(self, transport):
|
||||
self.transport = transport
|
||||
self._lost_connection.clear()
|
||||
self.lost_connection.clear()
|
||||
|
||||
def connection_lost(self, exc) -> None:
|
||||
self.transport = None
|
||||
self._lost_connection.set()
|
||||
self.lost_connection.set()
|
||||
|
||||
def data_received(self, data: bytes) -> None:
|
||||
try:
|
||||
|
|
@ -7,13 +7,13 @@ from string import ascii_letters
|
|||
from decimal import Decimal, ROUND_UP
|
||||
from google.protobuf.json_format import MessageToDict
|
||||
|
||||
from scribe.schema.base58 import Base58, b58_encode
|
||||
from scribe.error import MissingPublishedFileError, EmptyPublishedFileError
|
||||
from hub.schema.base58 import Base58, b58_encode
|
||||
from hub.error import MissingPublishedFileError, EmptyPublishedFileError
|
||||
|
||||
from scribe.schema.mime_types import guess_media_type
|
||||
from scribe.schema.base import Metadata, BaseMessageList
|
||||
from scribe.schema.tags import normalize_tag
|
||||
from scribe.schema.types.v2.claim_pb2 import (
|
||||
from hub.schema.mime_types import guess_media_type
|
||||
from hub.schema.base import Metadata, BaseMessageList
|
||||
from hub.schema.tags import normalize_tag
|
||||
from hub.schema.types.v2.claim_pb2 import (
|
||||
Fee as FeeMessage,
|
||||
Location as LocationMessage,
|
||||
Language as LanguageMessage
|
||||
|
|
@ -8,7 +8,7 @@ from coincurve.utils import (
|
|||
pem_to_der, lib as libsecp256k1, ffi as libsecp256k1_ffi
|
||||
)
|
||||
from coincurve.ecdsa import CDATA_SIG_LENGTH
|
||||
from scribe.schema.base58 import Base58
|
||||
from hub.schema.base58 import Base58
|
||||
|
||||
|
||||
if (sys.version_info.major, sys.version_info.minor) > (3, 7):
|
||||
|
|
@ -11,15 +11,15 @@ from hachoir.core.log import log as hachoir_log
|
|||
from hachoir.parser import createParser as binary_file_parser
|
||||
from hachoir.metadata import extractMetadata as binary_file_metadata
|
||||
|
||||
from scribe.schema import compat
|
||||
from scribe.schema.base import Signable
|
||||
from scribe.schema.mime_types import guess_media_type, guess_stream_type
|
||||
from scribe.schema.attrs import (
|
||||
from hub.schema import compat
|
||||
from hub.schema.base import Signable
|
||||
from hub.schema.mime_types import guess_media_type, guess_stream_type
|
||||
from hub.schema.attrs import (
|
||||
Source, Playable, Dimmensional, Fee, Image, Video, Audio,
|
||||
LanguageList, LocationList, ClaimList, ClaimReference, TagList
|
||||
)
|
||||
from scribe.schema.types.v2.claim_pb2 import Claim as ClaimMessage
|
||||
from scribe.error import InputValueIsNoneError
|
||||
from hub.schema.types.v2.claim_pb2 import Claim as ClaimMessage
|
||||
from hub.error import InputValueIsNoneError
|
||||
|
||||
|
||||
hachoir_log.use_print = False
|
||||
|
|
@ -3,9 +3,9 @@ from decimal import Decimal
|
|||
|
||||
from google.protobuf.message import DecodeError
|
||||
|
||||
from scribe.schema.types.v1.legacy_claim_pb2 import Claim as OldClaimMessage
|
||||
from scribe.schema.types.v1.certificate_pb2 import KeyType
|
||||
from scribe.schema.types.v1.fee_pb2 import Fee as FeeMessage
|
||||
from hub.schema.types.v1.legacy_claim_pb2 import Claim as OldClaimMessage
|
||||
from hub.schema.types.v1.certificate_pb2 import KeyType
|
||||
from hub.schema.types.v1.fee_pb2 import Fee as FeeMessage
|
||||
|
||||
|
||||
def from_old_json_schema(claim, payload: bytes):
|
||||
|
|
@ -1,6 +1,6 @@
|
|||
from google.protobuf.message import DecodeError
|
||||
from google.protobuf.json_format import MessageToDict
|
||||
from scribe.schema.types.v2.purchase_pb2 import Purchase as PurchaseMessage
|
||||
from hub.schema.types.v2.purchase_pb2 import Purchase as PurchaseMessage
|
||||
from .attrs import ClaimReference
|
||||
|
||||
|
||||
|
|
@ -2,11 +2,11 @@ import base64
|
|||
from typing import List, TYPE_CHECKING, Union, Optional, Dict, Set, Tuple
|
||||
from itertools import chain
|
||||
|
||||
from scribe.error import ResolveCensoredError
|
||||
from scribe.schema.types.v2.result_pb2 import Outputs as OutputsMessage
|
||||
from scribe.schema.types.v2.result_pb2 import Error as ErrorMessage
|
||||
from hub.error import ResolveCensoredError
|
||||
from hub.schema.types.v2.result_pb2 import Outputs as OutputsMessage
|
||||
from hub.schema.types.v2.result_pb2 import Error as ErrorMessage
|
||||
if TYPE_CHECKING:
|
||||
from scribe.db.common import ResolveResult
|
||||
from hub.db.common import ResolveResult
|
||||
INVALID = ErrorMessage.Code.Name(ErrorMessage.INVALID)
|
||||
NOT_FOUND = ErrorMessage.Code.Name(ErrorMessage.NOT_FOUND)
|
||||
BLOCKED = ErrorMessage.Code.Name(ErrorMessage.BLOCKED)
|
||||
|
|
@ -1,5 +1,5 @@
|
|||
from scribe.schema.base import Signable
|
||||
from scribe.schema.types.v2.support_pb2 import Support as SupportMessage
|
||||
from hub.schema.base import Signable
|
||||
from hub.schema.types.v2.support_pb2 import Support as SupportMessage
|
||||
|
||||
|
||||
class Support(Signable):
|
||||
0
hub/schema/types/v2/__init__.py
Normal file
0
hub/schema/types/v2/__init__.py
Normal file
1
hub/scribe/__init__.py
Normal file
1
hub/scribe/__init__.py
Normal file
|
|
@ -0,0 +1 @@
|
|||
from hub.scribe.network import LBCTestNet, LBCRegTest, LBCMainNet
|
||||
|
|
@ -2,20 +2,20 @@ import os
|
|||
import logging
|
||||
import traceback
|
||||
import argparse
|
||||
from scribe.env import Env
|
||||
from scribe.common import setup_logging
|
||||
from scribe.blockchain.service import BlockchainProcessorService
|
||||
from hub.common import setup_logging
|
||||
from hub.scribe.env import BlockchainEnv
|
||||
from hub.scribe.service import BlockchainProcessorService
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser(
|
||||
prog='scribe'
|
||||
)
|
||||
Env.contribute_to_arg_parser(parser)
|
||||
BlockchainEnv.contribute_to_arg_parser(parser)
|
||||
args = parser.parse_args()
|
||||
|
||||
try:
|
||||
env = Env.from_arg_parser(args)
|
||||
env = BlockchainEnv.from_arg_parser(args)
|
||||
setup_logging(os.path.join(env.db_dir, 'scribe.log'))
|
||||
block_processor = BlockchainProcessorService(env)
|
||||
block_processor.run()
|
||||
|
|
@ -3,12 +3,13 @@ import itertools
|
|||
import json
|
||||
import time
|
||||
import logging
|
||||
import ssl
|
||||
from functools import wraps
|
||||
|
||||
import aiohttp
|
||||
from prometheus_client import Gauge, Histogram
|
||||
from scribe import PROMETHEUS_NAMESPACE
|
||||
from scribe.common import LRUCacheWithMetrics, RPCError, DaemonError, WarmingUpError, WorkQueueFullError
|
||||
from hub import PROMETHEUS_NAMESPACE
|
||||
from hub.common import LRUCacheWithMetrics, RPCError, DaemonError, WarmingUpError, WorkQueueFullError
|
||||
|
||||
|
||||
log = logging.getLogger(__name__)
|
||||
|
|
@ -43,7 +44,7 @@ class LBCDaemon:
|
|||
)
|
||||
|
||||
def __init__(self, coin, url, max_workqueue=10, init_retry=0.25,
|
||||
max_retry=4.0):
|
||||
max_retry=4.0, daemon_ca_path=None):
|
||||
self.coin = coin
|
||||
self.logger = logging.getLogger(__name__)
|
||||
self.set_url(url)
|
||||
|
|
@ -54,9 +55,15 @@ class LBCDaemon:
|
|||
self.max_retry = max_retry
|
||||
self._height = None
|
||||
self.available_rpcs = {}
|
||||
self.connector = aiohttp.TCPConnector(ssl=False)
|
||||
self._block_hash_cache = LRUCacheWithMetrics(100000)
|
||||
self._block_cache = LRUCacheWithMetrics(2 ** 13, metric_name='block', namespace=NAMESPACE)
|
||||
ssl_context = None if not daemon_ca_path else ssl.create_default_context(
|
||||
purpose=ssl.Purpose.CLIENT_AUTH, capath=daemon_ca_path
|
||||
)
|
||||
if ssl_context:
|
||||
self.connector = aiohttp.TCPConnector(ssl_context=ssl_context)
|
||||
else:
|
||||
self.connector = aiohttp.TCPConnector(ssl=False)
|
||||
self._block_hash_cache = LRUCacheWithMetrics(1024, metric_name='block_hash', namespace=NAMESPACE)
|
||||
self._block_cache = LRUCacheWithMetrics(64, metric_name='block', namespace=NAMESPACE)
|
||||
|
||||
async def close(self):
|
||||
if self.connector:
|
||||
|
|
@ -176,6 +183,8 @@ class LBCDaemon:
|
|||
start = time.perf_counter()
|
||||
|
||||
def processor(result):
|
||||
if result is None:
|
||||
raise WarmingUpError
|
||||
err = result['error']
|
||||
if not err:
|
||||
return result['result']
|
||||
|
|
@ -200,6 +209,8 @@ class LBCDaemon:
|
|||
start = time.perf_counter()
|
||||
|
||||
def processor(result):
|
||||
if result is None:
|
||||
raise WarmingUpError
|
||||
errs = [item['error'] for item in result if item['error']]
|
||||
if any(err.get('code') == self.WARMING_UP for err in errs):
|
||||
raise WarmingUpError
|
||||
128
hub/scribe/db.py
Normal file
128
hub/scribe/db.py
Normal file
|
|
@ -0,0 +1,128 @@
|
|||
import hashlib
|
||||
import asyncio
|
||||
import array
|
||||
import time
|
||||
from typing import List
|
||||
from concurrent.futures.thread import ThreadPoolExecutor
|
||||
from bisect import bisect_right
|
||||
from hub.common import ResumableSHA256
|
||||
from hub.db import SecondaryDB
|
||||
|
||||
|
||||
class PrimaryDB(SecondaryDB):
|
||||
def __init__(self, coin, db_dir: str, reorg_limit: int = 200,
|
||||
cache_all_tx_hashes: bool = False,
|
||||
max_open_files: int = 64, blocking_channel_ids: List[str] = None,
|
||||
filtering_channel_ids: List[str] = None, executor: ThreadPoolExecutor = None,
|
||||
index_address_status=False, enforce_integrity=True):
|
||||
super().__init__(coin, db_dir, '', max_open_files, reorg_limit, cache_all_tx_hashes,
|
||||
blocking_channel_ids, filtering_channel_ids, executor, index_address_status,
|
||||
enforce_integrity=enforce_integrity)
|
||||
|
||||
def _rebuild_hashX_status_index(self, start_height: int):
|
||||
self.logger.warning("rebuilding the address status index...")
|
||||
prefix_db = self.prefix_db
|
||||
|
||||
def hashX_iterator():
|
||||
last_hashX = None
|
||||
for k in prefix_db.hashX_history.iterate(deserialize_key=False, include_value=False):
|
||||
hashX = k[1:12]
|
||||
if last_hashX is None:
|
||||
last_hashX = hashX
|
||||
if last_hashX != hashX:
|
||||
yield hashX
|
||||
last_hashX = hashX
|
||||
if last_hashX:
|
||||
yield last_hashX
|
||||
|
||||
def hashX_status_from_history(history: bytes) -> ResumableSHA256:
|
||||
tx_counts = self.tx_counts
|
||||
hist_tx_nums = array.array('I')
|
||||
hist_tx_nums.frombytes(history)
|
||||
digest = ResumableSHA256()
|
||||
digest.update(
|
||||
b''.join(f'{tx_hash[::-1].hex()}:{bisect_right(tx_counts, tx_num)}:'.encode()
|
||||
for tx_num, tx_hash in zip(
|
||||
hist_tx_nums,
|
||||
self.prefix_db.tx_hash.multi_get([(tx_num,) for tx_num in hist_tx_nums], deserialize_value=False)
|
||||
))
|
||||
)
|
||||
return digest
|
||||
|
||||
start = time.perf_counter()
|
||||
|
||||
if start_height <= 0:
|
||||
self.logger.info("loading all blockchain addresses, this will take a little while...")
|
||||
hashXs = list({hashX for hashX in hashX_iterator()})
|
||||
else:
|
||||
self.logger.info("loading addresses since block %i...", start_height)
|
||||
hashXs = set()
|
||||
for touched in prefix_db.touched_hashX.iterate(start=(start_height,), stop=(self.db_height + 1,),
|
||||
include_key=False):
|
||||
hashXs.update(touched.touched_hashXs)
|
||||
hashXs = list(hashXs)
|
||||
|
||||
self.logger.info(f"loaded {len(hashXs)} hashXs in {round(time.perf_counter() - start, 2)}s, "
|
||||
f"now building the status index...")
|
||||
op_cnt = 0
|
||||
hashX_cnt = 0
|
||||
for hashX in hashXs:
|
||||
hashX_cnt += 1
|
||||
key = prefix_db.hashX_status.pack_key(hashX)
|
||||
history = b''.join(prefix_db.hashX_history.iterate(prefix=(hashX,), deserialize_value=False, include_key=False))
|
||||
digester = hashX_status_from_history(history)
|
||||
status = digester.digest()
|
||||
existing_status = prefix_db.hashX_status.get(hashX, deserialize_value=False)
|
||||
existing_digester = prefix_db.hashX_history_hasher.get(hashX)
|
||||
if not existing_status:
|
||||
prefix_db.stash_raw_put(key, status)
|
||||
op_cnt += 1
|
||||
else:
|
||||
prefix_db.stash_raw_delete(key, existing_status)
|
||||
prefix_db.stash_raw_put(key, status)
|
||||
op_cnt += 2
|
||||
if not existing_digester:
|
||||
prefix_db.hashX_history_hasher.stash_put((hashX,), (digester,))
|
||||
op_cnt += 1
|
||||
else:
|
||||
prefix_db.hashX_history_hasher.stash_delete((hashX,), existing_digester)
|
||||
prefix_db.hashX_history_hasher.stash_put((hashX,), (digester,))
|
||||
op_cnt += 2
|
||||
if op_cnt > 100000:
|
||||
prefix_db.unsafe_commit()
|
||||
self.logger.info(f"wrote {hashX_cnt}/{len(hashXs)} hashXs statuses...")
|
||||
op_cnt = 0
|
||||
if op_cnt:
|
||||
prefix_db.unsafe_commit()
|
||||
self.logger.info(f"wrote {hashX_cnt}/{len(hashXs)} hashXs statuses...")
|
||||
self._index_address_status = True
|
||||
self.last_indexed_address_status_height = self.db_height
|
||||
self.write_db_state()
|
||||
self.prefix_db.unsafe_commit()
|
||||
self.logger.info("finished indexing address statuses")
|
||||
|
||||
def rebuild_hashX_status_index(self, start_height: int):
|
||||
return asyncio.get_event_loop().run_in_executor(self._executor, self._rebuild_hashX_status_index, start_height)
|
||||
|
||||
def apply_expiration_extension_fork(self):
|
||||
# TODO: this can't be reorged
|
||||
for k, v in self.prefix_db.claim_expiration.iterate():
|
||||
self.prefix_db.claim_expiration.stash_delete(k, v)
|
||||
self.prefix_db.claim_expiration.stash_put(
|
||||
(bisect_right(self.tx_counts, k.tx_num) + self.coin.nExtendedClaimExpirationTime,
|
||||
k.tx_num, k.position), v
|
||||
)
|
||||
self.prefix_db.unsafe_commit()
|
||||
|
||||
def write_db_state(self):
|
||||
"""Write (UTXO) state to the batch."""
|
||||
if self.db_height > 0:
|
||||
existing = self.prefix_db.db_state.get()
|
||||
self.prefix_db.db_state.stash_delete((), existing.expanded)
|
||||
self.prefix_db.db_state.stash_put((), (
|
||||
self.genesis_bytes, self.db_height, self.db_tx_count, self.db_tip,
|
||||
self.utxo_flush_count, int(self.wall_time), self.catching_up, self._index_address_status, self.db_version,
|
||||
self.hist_flush_count, self.hist_comp_flush_count, self.hist_comp_cursor,
|
||||
self.es_sync_height, self.last_indexed_address_status_height
|
||||
)
|
||||
)
|
||||
64
hub/scribe/env.py
Normal file
64
hub/scribe/env.py
Normal file
|
|
@ -0,0 +1,64 @@
|
|||
from hub.env import Env
|
||||
|
||||
|
||||
class BlockchainEnv(Env):
|
||||
def __init__(self, db_dir=None, max_query_workers=None, chain=None, reorg_limit=None,
|
||||
prometheus_port=None, cache_all_tx_hashes=None, blocking_channel_ids=None, filtering_channel_ids=None,
|
||||
db_max_open_files=64, daemon_url=None, hashX_history_cache_size=None,
|
||||
index_address_status=None, rebuild_address_status_from_height=None,
|
||||
daemon_ca_path=None, history_tx_cache_size=None,
|
||||
db_disable_integrity_checks=False):
|
||||
super().__init__(db_dir, max_query_workers, chain, reorg_limit, prometheus_port, cache_all_tx_hashes,
|
||||
blocking_channel_ids, filtering_channel_ids, index_address_status)
|
||||
self.db_max_open_files = db_max_open_files
|
||||
self.daemon_url = daemon_url if daemon_url is not None else self.required('DAEMON_URL')
|
||||
self.hashX_history_cache_size = hashX_history_cache_size if hashX_history_cache_size is not None \
|
||||
else self.integer('ADDRESS_HISTORY_CACHE_SIZE', 4096)
|
||||
self.rebuild_address_status_from_height = rebuild_address_status_from_height \
|
||||
if isinstance(rebuild_address_status_from_height, int) else -1
|
||||
self.daemon_ca_path = daemon_ca_path if daemon_ca_path else None
|
||||
self.history_tx_cache_size = history_tx_cache_size if history_tx_cache_size is not None else \
|
||||
self.integer('HISTORY_TX_CACHE_SIZE', 4194304)
|
||||
self.db_disable_integrity_checks = db_disable_integrity_checks
|
||||
|
||||
@classmethod
|
||||
def contribute_to_arg_parser(cls, parser):
|
||||
super().contribute_to_arg_parser(parser)
|
||||
env_daemon_url = cls.default('DAEMON_URL', None)
|
||||
parser.add_argument('--daemon_url', required=env_daemon_url is None,
|
||||
help="URL for rpc from lbrycrd or lbcd, "
|
||||
"<rpcuser>:<rpcpassword>@<lbrycrd rpc ip><lbrycrd rpc port>.",
|
||||
default=env_daemon_url)
|
||||
parser.add_argument('--daemon_ca_path', type=str, default='',
|
||||
help='Path to the lbcd ca file, used for lbcd with ssl')
|
||||
parser.add_argument('--db_disable_integrity_checks', action='store_true',
|
||||
help="Disable verifications that no db operation breaks the ability to be rewound",
|
||||
default=False)
|
||||
parser.add_argument('--db_max_open_files', type=int, default=64,
|
||||
help='This setting translates into the max_open_files option given to rocksdb. '
|
||||
'A higher number will use more memory. Defaults to 64.')
|
||||
parser.add_argument('--address_history_cache_size', type=int,
|
||||
default=cls.integer('ADDRESS_HISTORY_CACHE_SIZE', 4096),
|
||||
help="LRU cache size for address histories, used when processing new blocks "
|
||||
"and when processing mempool updates. Can be set in env with "
|
||||
"'ADDRESS_HISTORY_CACHE_SIZE'")
|
||||
parser.add_argument('--rebuild_address_status_from_height', type=int, default=-1,
|
||||
help="Rebuild address statuses, set to 0 to reindex all address statuses or provide a "
|
||||
"block height to start reindexing from. Defaults to -1 (off).")
|
||||
parser.add_argument('--history_tx_cache_size', type=int,
|
||||
default=cls.integer('HISTORY_TX_CACHE_SIZE', 4194304),
|
||||
help="Size of the lfu cache of txids in transaction histories for addresses. "
|
||||
"Can be set in the env with 'HISTORY_TX_CACHE_SIZE'")
|
||||
|
||||
@classmethod
|
||||
def from_arg_parser(cls, args):
|
||||
return cls(
|
||||
db_dir=args.db_dir, daemon_url=args.daemon_url, db_max_open_files=args.db_max_open_files,
|
||||
max_query_workers=args.max_query_workers, chain=args.chain, reorg_limit=args.reorg_limit,
|
||||
prometheus_port=args.prometheus_port, cache_all_tx_hashes=args.cache_all_tx_hashes,
|
||||
index_address_status=args.index_address_statuses,
|
||||
hashX_history_cache_size=args.address_history_cache_size,
|
||||
rebuild_address_status_from_height=args.rebuild_address_status_from_height,
|
||||
daemon_ca_path=args.daemon_ca_path, history_tx_cache_size=args.history_tx_cache_size,
|
||||
db_disable_integrity_checks=args.db_disable_integrity_checks
|
||||
)
|
||||
|
|
@ -2,10 +2,10 @@ import itertools
|
|||
import attr
|
||||
import typing
|
||||
from collections import defaultdict
|
||||
from scribe.blockchain.transaction.deserializer import Deserializer
|
||||
from hub.scribe.transaction.deserializer import Deserializer
|
||||
|
||||
if typing.TYPE_CHECKING:
|
||||
from scribe.db import HubDB
|
||||
from hub.scribe.db import PrimaryDB
|
||||
|
||||
|
||||
@attr.s(slots=True)
|
||||
|
|
@ -27,7 +27,7 @@ class MemPoolTxSummary:
|
|||
|
||||
|
||||
class MemPool:
|
||||
def __init__(self, coin, db: 'HubDB'):
|
||||
def __init__(self, coin, db: 'PrimaryDB'):
|
||||
self.coin = coin
|
||||
self._db = db
|
||||
self.txs = {}
|
||||
|
|
@ -4,12 +4,13 @@ import typing
|
|||
from typing import List
|
||||
from hashlib import sha256
|
||||
from decimal import Decimal
|
||||
from scribe.schema.base58 import Base58
|
||||
from scribe.schema.bip32 import PublicKey
|
||||
from scribe.common import hash160, hash_to_hex_str, double_sha256
|
||||
from scribe.blockchain.transaction import TxOutput, TxInput, Block
|
||||
from scribe.blockchain.transaction.deserializer import Deserializer
|
||||
from scribe.blockchain.transaction.script import OpCodes, P2PKH_script, P2SH_script, txo_script_parser
|
||||
from yarl import URL
|
||||
from hub.schema.base58 import Base58
|
||||
from hub.schema.bip32 import PublicKey
|
||||
from hub.common import hash160, hash_to_hex_str, double_sha256
|
||||
from hub.scribe.transaction import TxOutput, TxInput, Block
|
||||
from hub.scribe.transaction.deserializer import Deserializer
|
||||
from hub.scribe.transaction.script import OpCodes, P2PKH_script, P2SH_script, txo_script_parser
|
||||
|
||||
|
||||
HASHX_LEN = 11
|
||||
|
|
@ -58,6 +59,9 @@ class LBCMainNet:
|
|||
proportionalDelayFactor = 32
|
||||
maxTakeoverDelay = 4032
|
||||
|
||||
averageBlockOffset = 160.31130145580738
|
||||
genesisTime = 1466660400
|
||||
|
||||
@classmethod
|
||||
def sanitize_url(cls, url):
|
||||
# Remove surrounding ws and trailing /s
|
||||
|
|
@ -69,6 +73,9 @@ class LBCMainNet:
|
|||
url += f':{cls.RPC_PORT:d}'
|
||||
if not url.startswith('http://') and not url.startswith('https://'):
|
||||
url = 'http://' + url
|
||||
obj = URL(url)
|
||||
if not obj.user or not obj.password:
|
||||
raise CoinError(f'unparseable <user>:<pass> in daemon URL: "{url}"')
|
||||
return url + '/'
|
||||
|
||||
@classmethod
|
||||
|
|
@ -1,9 +1,9 @@
|
|||
import asyncio
|
||||
import logging
|
||||
import typing
|
||||
from hub.scribe.daemon import LBCDaemon, DaemonError
|
||||
if typing.TYPE_CHECKING:
|
||||
from scribe.blockchain.network import LBCMainNet
|
||||
from scribe.blockchain.daemon import LBCDaemon
|
||||
from hub.scribe.network import LBCMainNet
|
||||
|
||||
|
||||
def chunks(items, size):
|
||||
|
|
@ -42,8 +42,12 @@ class Prefetcher:
|
|||
while True:
|
||||
# Sleep a while if there is nothing to prefetch
|
||||
await self.refill_event.wait()
|
||||
if not await self._prefetch_blocks():
|
||||
await asyncio.sleep(self.polling_delay)
|
||||
try:
|
||||
if not await self._prefetch_blocks():
|
||||
await asyncio.sleep(self.polling_delay)
|
||||
except DaemonError as err:
|
||||
self.logger.warning("block prefetcher failed: '%s', retrying in 5 seconds", err)
|
||||
await asyncio.sleep(5)
|
||||
except Exception as e:
|
||||
if not isinstance(e, asyncio.CancelledError):
|
||||
self.logger.exception("block fetcher loop crashed")
|
||||
File diff suppressed because it is too large
Load diff
|
|
@ -1,9 +1,11 @@
|
|||
import sys
|
||||
import functools
|
||||
import typing
|
||||
import time
|
||||
from dataclasses import dataclass
|
||||
from struct import Struct
|
||||
from scribe.schema.claim import Claim
|
||||
from hub.schema.claim import Claim
|
||||
from hub.common import double_sha256
|
||||
|
||||
if (sys.version_info.major, sys.version_info.minor) > (3, 7):
|
||||
cachedproperty = functools.cached_property
|
||||
|
|
@ -84,6 +86,51 @@ class Tx(typing.NamedTuple):
|
|||
flag: typing.Optional[int] = None
|
||||
witness: typing.Optional[typing.List[typing.List[bytes]]] = None
|
||||
|
||||
def as_dict(self, coin):
|
||||
txid = double_sha256(self.raw)[::-1].hex()
|
||||
result = {
|
||||
"txid": txid,
|
||||
"hash": txid,
|
||||
"version": self.version,
|
||||
"size": len(self.raw),
|
||||
"vsize": len(self.raw),
|
||||
"weight": None, # FIXME: add this
|
||||
"locktime": self.locktime,
|
||||
"vin": [
|
||||
{
|
||||
"txid": txin.prev_hash[::-1].hex(),
|
||||
"vout": txin.prev_idx,
|
||||
"scriptSig": {
|
||||
"asm": None, # FIXME: add this
|
||||
"hex": txin.script.hex()
|
||||
},
|
||||
"sequence": txin.sequence
|
||||
} for txin in self.inputs
|
||||
],
|
||||
"vout": [
|
||||
{
|
||||
"value": txo.value / 1E8,
|
||||
"n": txo.nout,
|
||||
"scriptPubKey": {
|
||||
"asm": None, # FIXME: add this
|
||||
"hex": txo.pk_script.hex(),
|
||||
"reqSigs": 1, # FIXME: what if it isn't 1?
|
||||
"type": "nonstandard" if (txo.is_support or txo.is_claim or txo.is_update) else "pubkeyhash" if txo.pubkey_hash else "scripthash",
|
||||
"addresses": [
|
||||
coin.claim_address_handler(txo)
|
||||
]
|
||||
}
|
||||
} for txo in self.outputs
|
||||
],
|
||||
"hex": self.raw.hex()
|
||||
}
|
||||
for n, txo in enumerate(self.outputs):
|
||||
if txo.is_support or txo.is_claim or txo.is_update:
|
||||
result['vout'][n]["scriptPubKey"]["isclaim"] = txo.is_claim or txo.is_update
|
||||
result['vout'][n]["scriptPubKey"]["issupport"] = txo.is_support
|
||||
result['vout'][n]["scriptPubKey"]["subtype"] = "pubkeyhash" if txo.pubkey_hash else "scripthash"
|
||||
return result
|
||||
|
||||
|
||||
class TxInput(typing.NamedTuple):
|
||||
prev_hash: bytes
|
||||
|
|
@ -146,3 +193,21 @@ class Block(typing.NamedTuple):
|
|||
raw: bytes
|
||||
header: bytes
|
||||
transactions: typing.List[Tx]
|
||||
|
||||
@property
|
||||
def decoded_header(self):
|
||||
header = self.header
|
||||
version = int.from_bytes(header[:4], byteorder='little')
|
||||
ts = time.gmtime(int.from_bytes(header[100:104], byteorder='little'))
|
||||
timestamp = f"{ts.tm_year}-{ts.tm_mon}-{ts.tm_mday}"
|
||||
bits = int.from_bytes(header[104:108], byteorder='little')
|
||||
nonce = int.from_bytes(header[108:112], byteorder='little')
|
||||
return {
|
||||
'version': version,
|
||||
'prev_block_hash': header[4:36][::-1].hex(),
|
||||
'merkle_root': header[36:68][::-1].hex(),
|
||||
'claim_trie_root': header[68:100][::-1].hex(),
|
||||
'timestamp': timestamp,
|
||||
'bits': bits,
|
||||
'nonce': nonce
|
||||
}
|
||||
|
|
@ -1,9 +1,9 @@
|
|||
from scribe.common import double_sha256
|
||||
from scribe.blockchain.transaction import (
|
||||
from hub.common import double_sha256
|
||||
from hub.scribe.transaction import (
|
||||
unpack_le_int32_from, unpack_le_int64_from, unpack_le_uint16_from,
|
||||
unpack_le_uint32_from, unpack_le_uint64_from, Tx, TxInput, TxOutput
|
||||
)
|
||||
from scribe.blockchain.transaction.script import txo_script_parser
|
||||
from hub.scribe.transaction.script import txo_script_parser
|
||||
|
||||
|
||||
class Deserializer:
|
||||
Some files were not shown because too many files have changed in this diff Show more
Loading…
Reference in a new issue