88 lines
2.5 KiB
Markdown
88 lines
2.5 KiB
Markdown
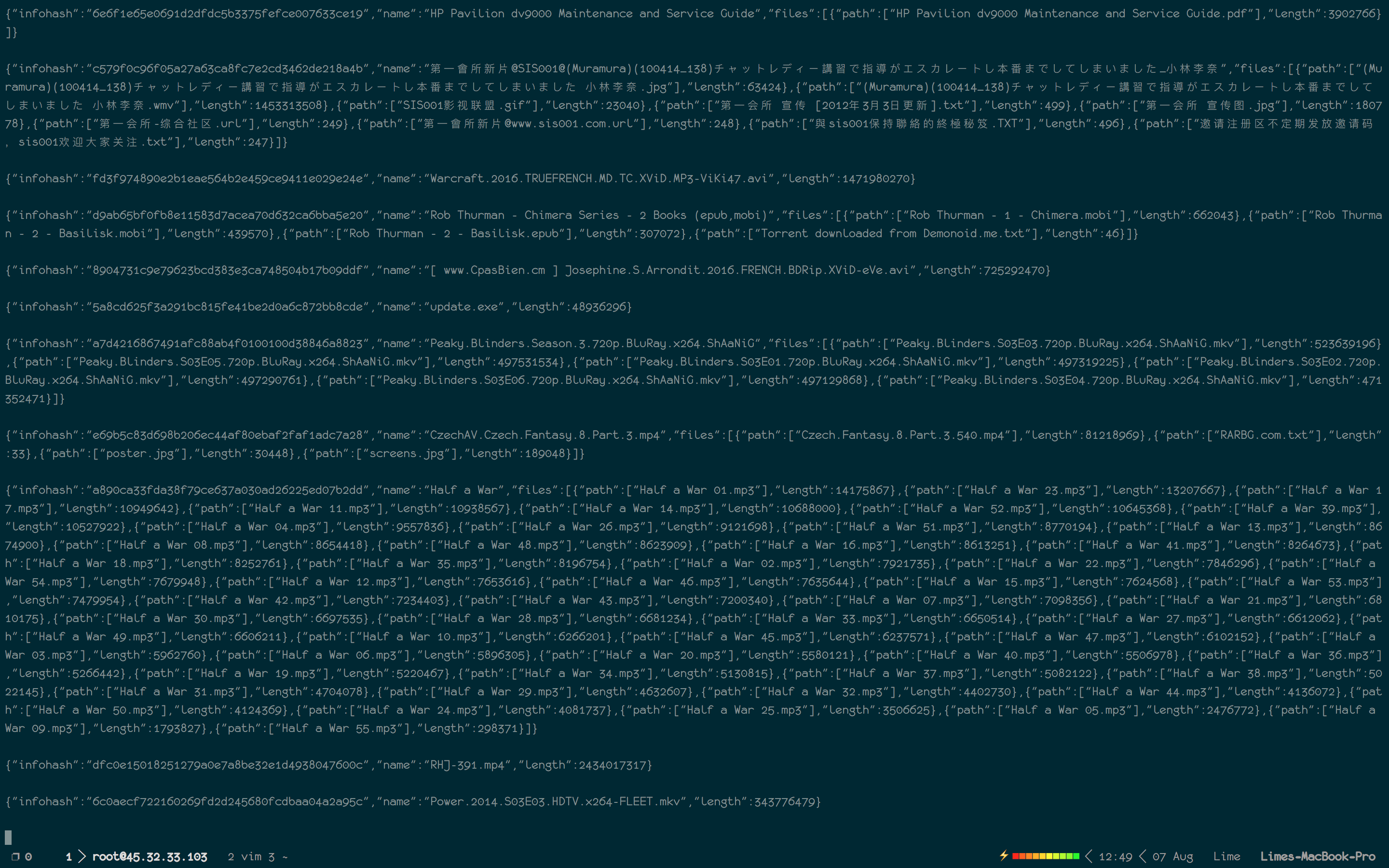
|
|
|
|
See the video on the [Youtube](https://www.youtube.com/watch?v=AIpeQtw22kc).
|
|
|
|
[中文版README](https://github.com/shiyanhui/dht/blob/master/README_CN.md)
|
|
|
|
## Introduction
|
|
|
|
DHT implements the bittorrent DHT protocol in Go. Now it includes:
|
|
|
|
- [BEP-3 (part)](http://www.bittorrent.org/beps/bep_0003.html)
|
|
- [BEP-5](http://www.bittorrent.org/beps/bep_0005.html)
|
|
- [BEP-9](http://www.bittorrent.org/beps/bep_0009.html)
|
|
- [BEP-10](http://www.bittorrent.org/beps/bep_0010.html)
|
|
|
|
It contains two modes, the standard mode and the crawling mode. The standard
|
|
mode follows the BEPs, and you can use it as a standard dht server. The crawling
|
|
mode aims to crawl as more metadata info as possiple. It doesn't follow the
|
|
standard BEPs protocol. With the crawling mode, you can build another [BTDigg](http://btdigg.org/).
|
|
|
|
[bthub.io](http://bthub.io) is a BT search engine based on the crawling mode.
|
|
|
|
## Installation
|
|
|
|
go get github.com/shiyanhui/dht
|
|
|
|
## Example
|
|
|
|
Below is a simple spider. You can move [here](https://github.com/shiyanhui/dht/blob/master/sample)
|
|
to see more samples.
|
|
|
|
```go
|
|
import (
|
|
"fmt"
|
|
"github.com/shiyanhui/dht"
|
|
)
|
|
|
|
func main() {
|
|
downloader := dht.NewWire(65535)
|
|
go func() {
|
|
// once we got the request result
|
|
for resp := range downloader.Response() {
|
|
fmt.Println(resp.InfoHash, resp.MetadataInfo)
|
|
}
|
|
}()
|
|
go downloader.Run()
|
|
|
|
config := dht.NewCrawlConfig()
|
|
config.OnAnnouncePeer = func(infoHash, ip string, port int) {
|
|
// request to download the metadata info
|
|
downloader.Request([]byte(infoHash), ip, port)
|
|
}
|
|
d := dht.New(config)
|
|
|
|
d.Run()
|
|
}
|
|
```
|
|
|
|
## Download
|
|
|
|
You can download the demo compiled binary file [here](https://github.com/shiyanhui/dht/files/407021/spider.zip).
|
|
|
|
## Note
|
|
|
|
- The default crawl mode configure costs about 300M RAM. Set **MaxNodes**
|
|
and **BlackListMaxSize** to fit yourself.
|
|
- Now it cant't run in LAN because of NAT.
|
|
|
|
## TODO
|
|
|
|
- [ ] NAT Traversal.
|
|
- [ ] Implements the full BEP-3.
|
|
- [ ] Optimization.
|
|
|
|
## FAQ
|
|
|
|
#### Why it is slow compared to other spiders ?
|
|
|
|
Well, maybe there are several reasons.
|
|
|
|
- DHT aims to implements the standard BitTorrent DHT protocol, not born for crawling the DHT network.
|
|
- NAT Traversal issue. You run the crawler in a local network.
|
|
- It will block ip which looks like bad and a good ip may be mis-judged.
|
|
|
|
## License
|
|
|
|
MIT, read more [here](https://github.com/shiyanhui/dht/blob/master/LICENSE)
|